Sztuczna inteligencja w astrofizyce
W swojej pracy astronomowie często korzystają z katalogów będących wynikiem wielkich przeglądów nieba. Zebrane w nich dane poddawane są różnorakim analizom. Ważne jest przy tym, aby katalogi charakteryzowały się jak największą kompletnością i jednorodnością. Niejednokrotnie podczas analizy statystycznej dobrze poznanych typów obiektów wykrywane są źródła rzadko spotykane lub wykazujące niezwykłe zachowanie. Dlatego też odpowiedni sposób klasyfikacji obserwowanych obiektów jest bardzo istotnym, o ile nie najistotniejszym krokiem, który należy wykonać przed przystąpieniem do zaawansowanego badania właściwości fizycznych obserwowanych obiektów niebieskich.
Cechy charakterystyczne.
Przy tworzeniu przeglądów nieba, bądź tych ukierunkowanych na wykrywanie konkretnych klas obiektów, bądź tych zbierających wszystkie możliwe dane z zadanego obszaru nieba, bardzo ważna jest znajomość cech charakterystycznych obiektów, które spodziewamy się zaobserwować. Ułatwia to proces samej detekcji oraz klasyfikacji zebranych danych i, co za tym idzie, szybkiego wydobycia ważnych informacji z przeprowadzonego przeglądu do dalszej analizy. Często zdarza się, że unikalna klasa obiektów, choć obecna w przeglądzie, nie zostaje wykryta, ponieważ wykazuje cechy charakterystyczne podobne do innych źródeł licznie wykrytych przez przegląd.
Dlatego jest bardzo ważne, by przegląd nieba był efektywny w mierzeniu różnych cech charakterystycznych obserwowanych źródeł. Jednak takie obserwacje są niezwykle trudne i kosztowne. (O wyzwaniach dotyczących pomiaru przesunięcia ku czerwieni pisaliśmy w Delcie 2/2016.) Zatem, chcąc uzyskać jak najliczniejsze próbki obiektów z danej klasy, które posłużą do dalszej analizy, często trzeba poświęcić tzw. "czystość" katalogu i pozwolić na pewien procent błędnych identyfikacji.
To jeszcze astronomia czy już informatyka?
Wraz ze wzrostem liczby przeprowadzanych kosmicznych misji obserwacyjnych oraz wzrostem wydajności procesu zbierania danych pojawił się problem z przetwarzaniem oraz identyfikacją istotnych informacji z terabajtów danych bezustannie napływających z satelitów.
Dlatego zamiast "ręcznych" technik klasyfikacji (takich jak diagramy kolor-kolor bądź kolor-strumień) wykorzystuje się automatyczne metody pozwalające na wykrywanie i separację różnych typów obiektów z minimalnym zaangażowaniem użytkownika przeglądu. Jednym z najbardziej użytecznych i najpowszechniej wykorzystywanych do tego celu algorytmów jest obecnie uczenie maszynowe (ang. machine learning). Metoda ta pozwala wykrywać pewne prawidłowości we wprowadzonych wektorach danych.
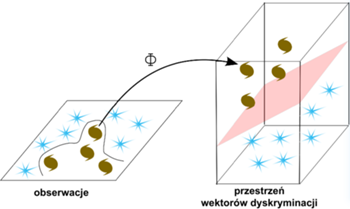
Z matematycznego punktu widzenia automatyczną klasyfikację można zdefiniować jako przekształcanie 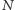 -wymiarowego wektora zawierającego mierzone parametry określające dany obiekt na tzw. wektor dyskryminacji. Przekształcenie to definiujemy tak, by w pewien sposób podkreślało lub nawet wyolbrzymiało charakterystyczne cechy poszczególnych obiektów. Dlatego bardzo ważny jest wybór przestrzeni cech charakterystycznych obiektów: optymalna klasyfikacja będzie miała miejsce wtedy, gdy różne typy źródeł będą występowały w innych obszarach danej przestrzeni wektorów dyskryminacji i będą się w jak najmniejszym stopniu przekrywały.
-wymiarowego wektora zawierającego mierzone parametry określające dany obiekt na tzw. wektor dyskryminacji. Przekształcenie to definiujemy tak, by w pewien sposób podkreślało lub nawet wyolbrzymiało charakterystyczne cechy poszczególnych obiektów. Dlatego bardzo ważny jest wybór przestrzeni cech charakterystycznych obiektów: optymalna klasyfikacja będzie miała miejsce wtedy, gdy różne typy źródeł będą występowały w innych obszarach danej przestrzeni wektorów dyskryminacji i będą się w jak najmniejszym stopniu przekrywały.
Jeżeli wykorzystywany przez nas przegląd nieba nie był specjalnie zaprojektowany do wykrywania interesujących nas obiektów, znalezienie odpowiedniego zestawu cech charakterystycznych może być bardzo trudne. W takim przypadku możemy użyć klasyfikatorów nienadzorowanych, stworzonych do wykrywania różnych prawidłowości w danych bez uprzedniej wiedzy na temat ich zawartości. Niestety, ten typ klasyfikacji bardzo silnie zależy od wyboru mierzonych parametrów.
W przestrzeni trójwymiarowej nietrudno sprawdzić, czy zadany punkt o współrzędnych 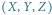 leży "nad" płaszczyzną opisaną równaniem
leży "nad" płaszczyzną opisaną równaniem 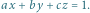 Odpowiedź będzie twierdząca, jeśli wyrażenie
Odpowiedź będzie twierdząca, jeśli wyrażenie 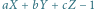 będzie miało taki sam znak jak
będzie miało taki sam znak jak 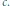 Jeśli zatem potrafimy wymyślić odwzorowanie
Jeśli zatem potrafimy wymyślić odwzorowanie 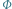 z przestrzeni zawierającej wyniki obserwacji do przestrzeni wektorów dyskryminacji rozdzielające rozważane obiekty jak na powyższym rysunku, zadanie ich klasyfikacji będzie niemal wykonane.
z przestrzeni zawierającej wyniki obserwacji do przestrzeni wektorów dyskryminacji rozdzielające rozważane obiekty jak na powyższym rysunku, zadanie ich klasyfikacji będzie niemal wykonane.
W przestrzeni trójwymiarowej nietrudno sprawdzić, czy zadany punkt o współrzędnych 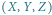 leży "nad" płaszczyzną opisaną równaniem
leży "nad" płaszczyzną opisaną równaniem 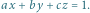 Odpowiedź będzie twierdząca, jeśli wyrażenie
Odpowiedź będzie twierdząca, jeśli wyrażenie 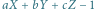 będzie miało taki sam znak jak
będzie miało taki sam znak jak 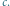 Jeśli zatem potrafimy wymyślić odwzorowanie
Jeśli zatem potrafimy wymyślić odwzorowanie 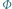 z przestrzeni zawierającej wyniki obserwacji do przestrzeni wektorów dyskryminacji rozdzielające rozważane obiekty jak na powyższym rysunku, zadanie ich klasyfikacji będzie niemal wykonane.
z przestrzeni zawierającej wyniki obserwacji do przestrzeni wektorów dyskryminacji rozdzielające rozważane obiekty jak na powyższym rysunku, zadanie ich klasyfikacji będzie niemal wykonane.
Każdy proces klasyfikacji może zostać usprawniony, jeżeli poszukiwane klasy obiektów zostaną sprecyzowane, a wartości ich cech charakterystycznych dokładnie opisane. Wtedy można stworzyć modele klas poszukiwanych obiektów, które posłużą jako wzór, który następnie będzie poszukiwany w danych. Takie typy klasyfikacji nazywane są nadzorowanymi i pozwalają na bardzo precyzyjne wyszukiwanie danego typu obiektów. Jeden z najczęściej obecnie używanych w astronomii klasyfikatorów nadzorowanych to maszyna wektorów nośnych (ang. support vector machine, SVM). Algorytm ten przekształca wektory zawierające wyniki obserwacji do przestrzeni 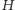 wektorów dyskryminacji, używając nieliniowej funkcji
wektorów dyskryminacji, używając nieliniowej funkcji 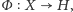 tak by granice między klasami można było opisać w jak najprostszy sposób. Na podstawie wektorów z próbki obiektów wzorcowych SVM dzieli przestrzeń
tak by granice między klasami można było opisać w jak najprostszy sposób. Na podstawie wektorów z próbki obiektów wzorcowych SVM dzieli przestrzeń 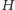 na odpowiednie klasy. W kolejnym kroku obiekty o nieznanej "przynależności klasowej" zostają przekształcone do przestrzeni
na odpowiednie klasy. W kolejnym kroku obiekty o nieznanej "przynależności klasowej" zostają przekształcone do przestrzeni 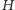 i w zależności od położenia obiektów względem granicy podziału - odpowiednio sklasyfikowane.
i w zależności od położenia obiektów względem granicy podziału - odpowiednio sklasyfikowane.
Algorytm SVM stosowany jest z sukcesami do generalnej identyfikacji obiektów takich jak gwiazdy, galaktyki, czy kwazary w wielkich przeglądach (między innymi AKARI, VIPERS, WISE), jak też do poszukiwania ich szczególnych podtypów.