Nowe pomysły
Czy przestępstwa można przewidzieć?
Walka z przestępczością jest jednym z podstawowych zadań każdej władzy, od jej skuteczności zależy jakość życia obywateli. Nic więc dziwnego, że rozmaite instytucje publiczne starają się zaprzęgać do tego celu metody statystyczne i uczenie maszynowe. Opowiem tu pokrótce, jak wygląda w praktyce "maszynowe" przewidywanie przestępstw i czy daje zadowalające rezultaty. Skupię się na miastach Ameryki Północnej, ponieważ tam tego typu systemy są najbardziej rozwinięte. Aby uniknąć rozważań natury prawnej, przestępstwem będę dla uproszczenia nazywał każde złamanie prawa, niezależnie od tego, czy formalnie kwalifikuje się jako czyn zabroniony, wykroczenie czy przestępstwo.
Skupię się na miastach Ameryki Północnej, ponieważ tam tego typu systemy są najbardziej rozwinięte. Aby uniknąć rozważań natury prawnej, przestępstwem będę dla uproszczenia nazywał każde złamanie prawa, niezależnie od tego, czy formalnie kwalifikuje się jako czyn zabroniony, wykroczenie czy przestępstwo.
Co dokładnie chcemy przewidzieć?
Kiedy myślimy o przewidywaniu przestępstw, wielu z nas przychodzi na myśl film "Raport mniejszości", oparty na opowiadaniu Philipa Dicka o tym samym tytule. Nazwisko przyszłego przestępcy było tam grawerowane na drewnianej kulce, a jej kolor określał typ niecnego czynu. Oczywiście w prawdziwym świecie możemy zapomnieć o tak dużej dokładności naszych prognoz. Warto natomiast spojrzeć na sprawę w sposób ilościowy - próbować przewidzieć, w jakich obszarach będzie miało miejsce najwięcej przestępstw, np. w ciągu tygodnia albo nawet miesiąca. Jeśli tam właśnie wyślemy dodatkowe patrole, być może zapobiegniemy największej liczbie przestępstw.
Jakie obszary się rozważa? Północnoamerykańskie miasta są formalnie podzielone na rewiry policyjne o takich rozmiarach, aby jeden funkcjonariusz mógł patrolować jeden rewir na piechotę. Prognozą może być wybranie "najgorszych" (o największej przestępczości) rewirów. Często też nakłada się na miasto regularną prostokątną siatkę o oczku o rozmiarach rzędu 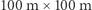 (dosyć zgodną z układem ulic) i wskazuje "najgorsze" komórki. Można również nie narzucać żadnego odgórnego podziału i pozwolić algorytmom znaleźć nieregularne "najgorsze" obszary wedle ich uznania.
(dosyć zgodną z układem ulic) i wskazuje "najgorsze" komórki. Można również nie narzucać żadnego odgórnego podziału i pozwolić algorytmom znaleźć nieregularne "najgorsze" obszary wedle ich uznania.
Jak zmierzyć jakość naszych przewidywań? W związku z niewielką liczbą policjantów wybrane fragmenty miasta muszą być jego malutką częścią (łącznie ok. 1%), tak aby do każdego z nich rzeczywiście można było skierować patrol. Dlatego nie ma sensu np. sprawdzanie, jaki procent przestępstw "trafiliśmy", gdyż wrtość takiej funkcji możemy zwiększać przez wskazywanie coraz większych obszarów. Przykładem funkcji wolnej od tej wady jest tzw. wskaźnik dokładności prognozowania dany wzorem

gdzie:
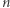 to łączna liczba przestępstw popełnionych w wybranych obszarach,
to łączna liczba przestępstw popełnionych w wybranych obszarach,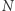 to liczba przestępstw popełnionych w całym mieście,
to liczba przestępstw popełnionych w całym mieście,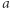 to łączna powierzchnia wybranych obszarów,
to łączna powierzchnia wybranych obszarów,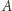 to powierzchnia miasta.
to powierzchnia miasta.
Musimy jednak przyjąć dolne ograniczenie dla 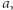 inaczej algorytm zapewne wskaże obszar o powierzchni rzędu 1 m
inaczej algorytm zapewne wskaże obszar o powierzchni rzędu 1 m 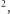 który policji do niczego się nie przyda.
który policji do niczego się nie przyda.
Czym się kierować?
Amerykańskie miasta za darmo udostępniają w Internecie aktualne pełne wykazy popełnionych przestępstw wraz z datami i współrzędnymi. Możemy zatem swobodnie pracować z kompletnymi danymi historycznymi. To komfortowa sytuacja. W tym miejscu należy wspomnieć, że polska policja, niestety, nie jest uprawniona do ujawniania tego typu danych.
Czym jeszcze możemy się kierować przy przewidywaniu przestępstw? Co może wpływać na przyszłe przestępstwa, ale nie być "zakodowane" w danych historycznych? Moim zdaniem tylko przyszłe wydarzenia. Ale czy można je przewidzieć łatwiej niż same przestępstwa? Niektórzy decydują się na użycie w swoich modelach dodatkowych danych demograficznych: struktury narodowości, wieku, wykształcenia, zarobków itp. w poszczególnych częściach miasta. Istnieją prace próbujące wyłuskać przydatne informacje ze zdjęć z Google Maps czy z wiadomości na Twitterze. Korzysta się też z prognoz pogody. Podstawowym źródłem informacji pozostają jednak dane historyczne.
Jak to zrobić?
Kiedy zastanawiamy się, w jaki sposób przewidywać przyszłe przestępstwa, pierwszy pomysł brzmi: po prostu zliczmy historyczne przestępstwa w poszczególnych rewirach czy komórkach i wskażmy te z najgorszą przeszłością. Co ciekawe, tak proste (i pesymistyczne) podejście może być skuteczne! Pozwoliło ono zespołowi deepsense.ai wygrać w 2017 roku konkurs na najlepszą prognozę przestępstw w mieście Portland w stanie Oregon.
W naszym algorytmie stworzonym na potrzeby konkursu nieco podrasowaliśmy powyższą ogólną ideę. Historyczne przestępstwa należy ważyć: przestępstwo popełnione wczoraj jest "ważniejsze" od mającego miejsce kilka lat temu, przestępstwo popełnione rok temu o tej samej porze jest "ważniejsze" od popełnionego w innym miesiącu poprzedniego roku. Jeśli przestępstwo zostało popełnione metr od (sztucznej) granicy rewiru/komórki, być może pociągnie za sobą kolejne tuż za tą granicą. Na pytanie, jak istotne są takie efekty starzenia się, sezonowości i "promieniowania" przestępstw, odpowiedzieliśmy w sposób charakterystyczny dla uczenia maszynowego: pozwoliliśmy algorytmowi samemu skalibrować ich znaczenie.
Oczywiście z sukcesami przewiduje się przestępstwa również przy użyciu bardziej wyrafinowanych metod statystycznych. Opowiem tutaj o jednej z nich. Skupmy się na włamaniach. Charakteryzują się one dwiema cechami: są bardzo rzadkie (ok. 20 tygodniowo w Portland) oraz włamywacze często wracają do poprzednio okradzionego mieszkania lub odwiedzają jego najbliższą okolicę (ponieważ znają już teren). Podobnie "zachowują się" wstrząsy sejsmiczne: są rzadkie oraz pierwszemu wstrząsowi towarzyszą zwykle wstrząsy wtórne. Dlatego przeszczepia się metody sejsmologiczne na grunt przewidywania włamań.
Trzęsienia ziemi modeluje się za pomocą tzw. samonapędzających się czasoprzestrzennych procesów punktowych. Działają one tak, że domyślne prawdopodobieństwo wystąpienia zdarzenia (wstrząsu) w danym miejscu w danej chwili jest niskie, ale jeśli już zdarzenie nastąpi, prawdopodobieństwo, że powtórzy się za chwilę w tym samym miejscu, znacznie wzrasta. Przy tworzeniu modelu trzeba uważać, żeby nie napędzał się za bardzo, inaczej "wybuchnie" - będzie wskazywał, że w danym miejscu zdarzenie nastąpi w każdej przyszłej chwili. Opierające się na tego typu metodach systemy przewidywania włamań charakteryzują się wysoką jakością.
Czy to naprawdę działa?
Automatyczne systemy przewidywania przestępstw funkcjonują w wielu amerykańskich miastach, zostały również wdrożone m.in. w aglomeracjach Wielkiej Brytanii, Holandii czy Chin. Spełniają tam swoją rolę - redukują przestępczość. Na przykład po uruchomieniu takiego systemu liczba włamań w mieście Santa Cruz w Kalifornii spadła o 20%. Tego typu rozwiązania bywają jednak przyjmowane przez policjantów niechętnie. Myślę, że przede wszystkim dlatego, że nie obejmują wszystkich sytuacji. Nie nadają się np. w przypadku, kiedy wszyscy wiedzą, że sprawcą włamań czy zniszczeń mienia w okolicy jest dopiero co wypuszczony na zwolnienie warunkowe recydywista i złapanie go na gorącym uczynku jest tylko kwestią czasu i włożonych sił.
Miejmy nadzieję, że ścisła współpraca instytucji publicznych ze statystykami i osobami parającymi się uczeniem maszynowym pozwoli na zwiększenie skuteczności systemów przewidujących przestępstwa i bardziej entuzjastyczne używanie ich przez policjantów. I miejmy też nadzieję, że ceną za to nie będzie inwigilacja obywateli przypominająca tę z "Raportu mniejszości".