Jak się mierzy nierówności społeczno-ekonomiczne?

Nie ma chyba zagadnienia ekonomicznego, które by zdominowało debatę publiczną w ostatniej dekadzie tak bardzo jak rosnące nierówności. Niemalże każdy tydzień przynosi w mediach informację dotyczącą nierówności dochodowych czy majątkowych, np. ostatnio oszacowania rozmiarów unikania podatków przez firmy i osoby bogate na podstawie danych z afery Panama Papers. Unikanie to prowadzi do zaniżenia oszacowań nierówności majątkowych. Najczęściej wskazywane przyczyny rosnących nierówności to wzrost udziału dochodów z kapitału, postęp technologiczny, który nagradza umiejętności umysłowe korzystniej niż fizyczne, prowadząc do rozwarstwienia płac, procesy globalizacyjne i postępująca automatyzacja. Jako konsekwencje rosnących nierówności wskazuje się napięcia społeczne i polaryzację poglądów politycznych. W istocie nierówności są ważnym zjawiskiem społecznym. W niniejszym artykule przyjrzymy się temu, jak się je w ogóle mierzy.
Co ciekawe, nierówności jako zagadnienie badawcze znajdowały się długo poza głównym nurtem ekonomii. Ekonomiści uważali, że gospodarki znajdują się na ścieżce wzrostu, który w długim okresie sprzyja spadkowi nierówności. Popularne było przekonanie, że w początkowym okresie wzrostu gospodarczego nierówności wzrastają, gdyż tylko nieliczni korzystają z owoców wzrostu, ale w długim okresie wzrost wzbogaca każdego w sposób, który niweluje rozwarstwienie. Przekonanie to było oparte jednak na krótkich seriach danych o dochodach. Oszacowania były więc podatne na wpływ dużych jednostkowych zdarzeń jak Wielki Kryzys czy II Wojna Światowa, które doprowadziły do zniszczenia majątków i przez to czasowego spadku nierówności. Obecne zainteresowanie nierównościami bierze się z faktu, że rosną one systematycznie w krajach rozwiniętych i są na poziomie tych z początku XX wieku oraz z powodu popularności książki Thomasa Piketty'ego Kapitał w XXI wieku wydanej pięć lat temu. Piketty wraz z zespołem 30 ekonomistów z różnych krajów dostarczył nowej serii danych do analizy nierówności dochodowych i majątkowych. Wymagało to dotarcia do archiwów blisko 50 krajów świata. Większość tych danych jest dziś dostępna online w Światowej Bazie Danych o Najwyższych Dochodach. Piketty i jego zespół badali ewolucję udziału górnego decyla, percentyla, a czasem nawet 0,1% rozkładu dochodów w łącznym dochodzie. Jest to jedna z miar nierówności. Innym przyjrzymy się obecnie.
Nierówność jest pojęciem niełatwym do uchwycenia. Nie wszystkie pojęcia w naukach społecznych takie są. Przykładowo, bezrobocie od razu nasuwa na myśl funkcję, jakiej mamy użyć do jego pomiaru - iloraz. W przypadku nierówności mamy tylko pewne intuicje co do tego, czym ona jest, stąd pojęcie to definiuje się aksjomatycznie, to znaczy, intuicje zapisane są w formie aksjomatów. Wariancja szybko przychodzi na myśl jako miara nierówności, niemniej nie jest ona odporna na skalowania, a intuicja nam podpowiada, że to, czy mierzymy dochód w złotych czy w tysiącach złotych, nie powinno mieć wpływu na rozwarstwienie. Stąd dalej nasuwa się myśl, że niezmienniczość ze względu na proporcjonalne skalowanie dochodów jest rozsądnym wymaganiem wobec indeksu nierówności. Własność tę nazywamy homogenicznością i jest to jedna z czterech tak zwanych podstawowych własności miar nierówności. Jeśli funkcja spełnia je wszystkie, to mówimy, że jest indeksem nierówności.
Innym podstawowym aksjomatem teorii pomiaru nierówności jest tzw. transfer Pigou-Dalton, od nazwisk dwóch ekonomistów, którzy zaproponowali go w latach 20. XX wieku. Aksjomat ten mówi, że nierówność spada po takim transferze dochodu od bogatego do biednego, który nie zmienia ich wzajemnego uporządkowania. A zatem po transferze bogaty nadal pozostaje bogatszy od biednego, ale są oni teraz bliżej siebie w rozkładzie dochodu. Wydaje się faktycznie naturalne, że nierówność w takim przypadku została zmniejszona, więc indeks nierówności powinien odnotować spadek. Kolejny aksjomat stwierdza, że miary nierówności powinny być "ślepe" na to, kto posiada dany dochód. Innymi słowy, powinny traktować wszystkich symetrycznie lub anonimowo, jak określał to polski logik Kazimierz Ajdukiewicz, zasłużony dla rozwoju blisko powiązanej z teorią nierówności aksjomatycznej teorii sprawiedliwości. Formalnie anonimowość oznacza, że indeks nie zmienia się ze względu na permutacje dochodów między osobami. Czwarta podstawowa własność indeksów nierówności sprawia, że mogą być porównywane rozkłady o różnym rozmiarze populacji. Ściślej, indeks nie zmienia się, jeśli zreplikujemy dochody w populacji.
Cztery podstawowe aksjomaty zostawiają wiele swobody w konstrukcji różnych miar. Miary te spełniają lub nie inne własności, których nie uważamy już za podstawowe, ale które również wyrażają pewne nasze intuicje odnośnie tego, czym jest nierówność. Przykładowo, niektórzy autorzy uważają, że miary nierówności powinny różnie traktować transfery Pigou-Dalton, które mają miejsce w dole rozkładu i w górze rozkładu. Własność ta nazywa się wrażliwością na transfery mieszane (łącznie u góry i u dołu). Konstruowane są miary, które ją mają, ale, na przykład, popularna miara, jaką jest współczynnik zmienności, jej nie ma. Generalnie zatem indeksy nierówności wielokrotnie się ze sobą nie zgadzają i różnie porządkują dwa rozkłady, co nie jest pożądane, gdyż wybór między poszczególnymi indeksami jest arbitralny. Naturalne jest więc pytanie, czy istnieją takie porównania, odnośnie których wszystkie miary, które spełniają cztery podstawowe własności, są zgodne? Formalnie, jaka jest największa (w sensie inkluzji) taka relacja na rozkładach, że jeśli rozkład 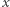 jest lepszy niż rozkład
jest lepszy niż rozkład 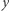 w sensie tej relacji, to wszystkie indeksy nierówności, które spełniają cztery podstawowe własności, mają wartość w
w sensie tej relacji, to wszystkie indeksy nierówności, które spełniają cztery podstawowe własności, mają wartość w 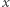 niższą niż w
niższą niż w 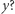
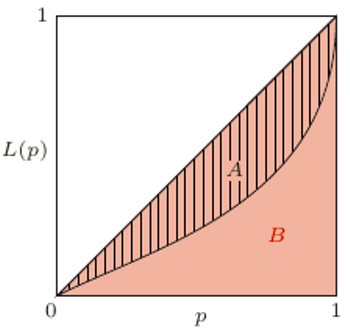
Rys. 1 Krzywa Lorenza
Tą relacją jest porządek częściowy implikowany przez tzw. krzywą Lorenza. Porządkujemy dochody rosnąco. Krzywa Lorenza podaje skumulowany udział w łącznym dochodzie, który przypada  najbiedniejszej części populacji. Jeśli wszystkie dochody byłyby równe, wówczas
najbiedniejszej części populacji. Jeśli wszystkie dochody byłyby równe, wówczas  najbiedniejsza część populacji posiadałaby dokładnie
najbiedniejsza część populacji posiadałaby dokładnie  -tą część łącznego dochodu. Krzywa Lorenza jest wtedy diagonalą między punktami
-tą część łącznego dochodu. Krzywa Lorenza jest wtedy diagonalą między punktami 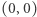 a
a 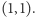 Gdy dochody stają się bardziej zróżnicowane, wówczas krzywa oddala się od diagonali w stronę brzegów trójkąta, jak pokazuje rysunek obok. Na brzegu mamy rozkład, w którym tylko jeden dochód jest dodatni - inni nie posiadają nic; jest to rozkład uważany za najbardziej nierówny. Mówimy, że rozkład
Gdy dochody stają się bardziej zróżnicowane, wówczas krzywa oddala się od diagonali w stronę brzegów trójkąta, jak pokazuje rysunek obok. Na brzegu mamy rozkład, w którym tylko jeden dochód jest dodatni - inni nie posiadają nic; jest to rozkład uważany za najbardziej nierówny. Mówimy, że rozkład  jest bardziej równy niż rozkład
jest bardziej równy niż rozkład  jeśli krzywa Lorenza rozkładu
jeśli krzywa Lorenza rozkładu  leży powyżej krzywej Lorenza rozkładu
leży powyżej krzywej Lorenza rozkładu 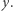 Miarą nierówności, która zawdzięcza swą popularność z powodu bliskich związków z krzywą Lorenza, jest indeks Giniego. Indeks ten mierzy stosunek pola obszaru
Miarą nierówności, która zawdzięcza swą popularność z powodu bliskich związków z krzywą Lorenza, jest indeks Giniego. Indeks ten mierzy stosunek pola obszaru 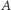 do pola zamalowanego trójkąta
do pola zamalowanego trójkąta 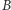 z rysunku obok. Wartość wskaźnika Giniego dla Polski wynosi obecnie około
z rysunku obok. Wartość wskaźnika Giniego dla Polski wynosi obecnie około 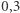 na podstawie danych ankietowych o dochodach, a na podstawie (nielicznych niestety) danych z zeznań podatkowych indeks ma wartość
na podstawie danych ankietowych o dochodach, a na podstawie (nielicznych niestety) danych z zeznań podatkowych indeks ma wartość 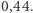 Rozbieżności te wynikają ze słabej reprezentacji osób o wysokich dochodach w badaniach ankietowych. Różnice są istotne. Wartość
Rozbieżności te wynikają ze słabej reprezentacji osób o wysokich dochodach w badaniach ankietowych. Różnice są istotne. Wartość 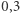 plasuje nas obok zamożnych państw Zachodu, zaś wartość
plasuje nas obok zamożnych państw Zachodu, zaś wartość 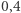 obok Rosji.
obok Rosji.
Gdy krzywa Lorenza rozkładu  jest ponad krzywą dla rozkładu
jest ponad krzywą dla rozkładu 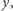 wówczas wszystkie indeksy
wówczas wszystkie indeksy 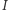 spełniające podstawowe własności pokazują, że
spełniające podstawowe własności pokazują, że 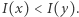 A zatem porządek częściowy generowany przez zbiór wszystkich miar, które spełniają cztery podstawowe aksjomaty, to właśnie porządek zadany przez krzywą Lorenza. W praktyce zatem, aby stwierdzić, który rozkład jest równiejszy, nie trzeba sprawdzać po kolei wszystkich znanych miar, wystarczy porównać krzywe Lorenza. Niestety, nie zawsze uzyskamy odpowiedź. Gdy krzywe przecinają się, wówczas nie możemy nic stwierdzić. Krzywa Lorenza jest porządkiem częściowym, nie wszystkie rozkłady można porównać za jej pomocą. Co więcej, gdy krzywe Lorenza się przecinają, istnieje zarówno miara nierówności
A zatem porządek częściowy generowany przez zbiór wszystkich miar, które spełniają cztery podstawowe aksjomaty, to właśnie porządek zadany przez krzywą Lorenza. W praktyce zatem, aby stwierdzić, który rozkład jest równiejszy, nie trzeba sprawdzać po kolei wszystkich znanych miar, wystarczy porównać krzywe Lorenza. Niestety, nie zawsze uzyskamy odpowiedź. Gdy krzywe przecinają się, wówczas nie możemy nic stwierdzić. Krzywa Lorenza jest porządkiem częściowym, nie wszystkie rozkłady można porównać za jej pomocą. Co więcej, gdy krzywe Lorenza się przecinają, istnieje zarówno miara nierówności 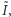 dla której zachodzi
dla której zachodzi 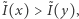 jak i taka
jak i taka 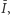 dla której
dla której 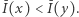
Wtedy, gdy nie możemy porównać rozkładów za pomocą krzywej Lorenza, odwołujemy się do indeksów, które dają porządek liniowy, czyli zawsze odpowiedzą, który rozkład jest równiejszy. To, jak już wspomnieliśmy, odbywa się za cenę arbitralności zawartej w konkretnej postaci funkcyjnej indeksu. Arbitralność ta jednak jest zmniejszona, jeżeli znamy zbiór aksjomatów charakteryzujących dany indeks. Mówimy, że zbiór aksjomatów charakteryzuje dany indeks, jeśli indeks nie tylko spełnia te aksjomaty, ale też jest przez nie implikowany. Jeśli taką charakteryzację dla rozważanych przez nas indeksów znamy, wówczas wybór odbywa się między aksjomatami. A priori bowiem, z samej postaci funkcyjnej indeksu ciężko jest odczytać, jakie postulaty etyczne o nierówności on implikuje, np. jak traktuje transfery mieszane. Znając charakteryzację, lepiej rozumiemy wyniki, które otrzymujemy przy użyciu indeksu 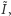 w porównaniu do tych, które daje indeks
w porównaniu do tych, które daje indeks 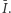

W toku kilkudziesięciu lat rozwoju teorii pomiaru nierówności zaproponowano wiele aksjomatów i indeksów. Poza podstawowymi zwrócimy jeszcze uwagę na dwa. Często w badaniach empirycznych chcemy uzyskać zdezagregowany obraz łącznej nierówności, to jest w podziale na różne grupy społeczno-ekonomiczne (ze względu na płeć, wiek, miejsce zamieszkania, kolor skóry itp.). Pozwala to wyśledzić, które grupy dokładają się najbardziej do łącznej nierówności i powinny być celem polityki redukującej nierówności. Naturalnym wymaganiem jest, by dało się zdekomponować nierówność łączną na część wewnątrzgrupową, czyli sumę nierówności w poszczególnych grupach zważonych ich udziałem w łącznej populacji, oraz część międzygrupową, czyli nierówność między średnimi dochodami w grupach (wówczas wszelkie nierówności wewnątrzgrupowe zostają zniwelowane, bo każda osoba w grupie "dostaje" średni dochód grupy). Okazuje się, że jedyną klasą indeksów, które można w ten sposób zdekomponować, są tzw. indeksy uogólnionej entropii. Jest to więc z jednej strony wymaganie bardzo pożądane w empirycznych zastosowaniach, a z drugiej bardzo restrykcyjne. Popularny indeks Giniego nie należy do tej klasy.
Ostatnią własnością indeksów, na którą zwrócimy uwagę, jest wymaganie, by indeks był istotny w sensie normatywnym, to jest, by był związany z funkcją dobrobytu. Dlaczego bowiem w ogóle interesuje nas nierówność? Dlatego, że uważamy, iż nierówność jest w pewnym sensie niepożądana, czyli że łączy się z niższym dobrobytem. Funkcje dobrobytu "dbają" zarówno o równość, jak i średni dochód. Najprostszym przykładem funkcji dobrobytu jest iloczyn średniego dochodu i 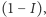 gdzie
gdzie 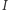 to, na przykład, indeks Giniego. Dla ustalonego dochodu średniego funkcja dobrobytu maleje wraz z wyższą nierównością. Funkcja taka wyraża to, że ważny jest zarówno rozmiar ciasta, jak i jego podział. W ekonomii słynna jest debata o wymienności efektywności (rozmiaru) i sprawiedliwości (podziału), ale badania empiryczne w ostatnich latach pokazują, że możemy mieć raczej do czynienia z komplementarnością. Dla konkretnego rozkładu dochodów możemy zadać pytanie: jaki jest najmniejszy taki dochód, że dany każdej osobie doprowadziłby do tego samego poziomu dobrobytu co rozważany rozkład? Dochód ten to równo rozłożony dochód równoważny
to, na przykład, indeks Giniego. Dla ustalonego dochodu średniego funkcja dobrobytu maleje wraz z wyższą nierównością. Funkcja taka wyraża to, że ważny jest zarówno rozmiar ciasta, jak i jego podział. W ekonomii słynna jest debata o wymienności efektywności (rozmiaru) i sprawiedliwości (podziału), ale badania empiryczne w ostatnich latach pokazują, że możemy mieć raczej do czynienia z komplementarnością. Dla konkretnego rozkładu dochodów możemy zadać pytanie: jaki jest najmniejszy taki dochód, że dany każdej osobie doprowadziłby do tego samego poziomu dobrobytu co rozważany rozkład? Dochód ten to równo rozłożony dochód równoważny 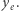 Oznaczmy przez
Oznaczmy przez 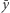 średni dochód w rozważanym rozkładzie. Wówczas
średni dochód w rozważanym rozkładzie. Wówczas 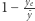 mierzy część średniego dochodu, który jest "stracony" z powodu nierówności. Jest to dobra miara nierówności. Jej konkretna postać zależy od wybranej funkcji dobrobytu, od której
mierzy część średniego dochodu, który jest "stracony" z powodu nierówności. Jest to dobra miara nierówności. Jej konkretna postać zależy od wybranej funkcji dobrobytu, od której 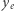 pochodzi. Najpopularniejszy z tej klasy jest indeks Atkinsona, gdzie funkcja dobrobytu to potęga średniego dochodu, a wykładnik potęgi ma ładną interpretację jako stopień awersji do nierówności w społeczeństwie. Można później estymować z danych o dochodach, jaki stopień awersji mają różne społeczeństwa.
pochodzi. Najpopularniejszy z tej klasy jest indeks Atkinsona, gdzie funkcja dobrobytu to potęga średniego dochodu, a wykładnik potęgi ma ładną interpretację jako stopień awersji do nierówności w społeczeństwie. Można później estymować z danych o dochodach, jaki stopień awersji mają różne społeczeństwa.

Dotychczasowa prezentacja teorii pomiaru nierówności odnosiła się tylko do jednej zmiennej i to zmiennej kardynalnej. Taką zmienną jest dochód i ekonomiści długo byli zainteresowani wyłącznie nierównościami dochodowymi, a wiadomo, że dla dobrobytu jednostki istotny jest nie tylko dochód, ale również zdrowie, edukacja, czyste powietrze, bezpieczeństwo osobiste, prawa polityczne i inne. Tradycyjnie sądzono jednak, że tego typu dobra niekonsumpcyjne mogą być ujęte w rachunkach dochodowych z odpowiednimi cenami. Nawet jeśli jednak znalibyśmy te ceny, zakładalibyśmy wówczas nieskończoną substytucję między tymi różnymi dobrami, co jest mocnym wymaganiem. Ponadto, badania empiryczne pokazują, że czynniki, które przyczyniają się do wzrostu nierówności dochodowych (np. różne zapisy dotyczące płacy minimalnej), niekoniecznie są tożsame z czynnikami, które wywołują nierówność w innych zmiennych, np. w edukacji (na którą ma wpływ, na przykład, dostępność szkół publicznych czy regulacje dotyczące pracy dzieci w krajach rozwijających się). Dochód nie jest więc dobrym "przybliżeniem" zachowania innych wymiarów dobrobytu. To zainteresowanie innymi wymiarami dobrobytu ma dla teorii pomiaru nierówności dwie konsekwencje, mianowicie, konieczność rozwoju teorii pomiaru nierówności wielowymiarowych oraz teorii pomiaru nierówności dla zmiennych porządkowych. Pozadochodowe wymiary dobrobytu mają bowiem często postać uporządkowanych kategorii, np. pytamy respondenta o to, jak ocenia stan swojego zdrowia i ma do wyboru jedną z pięciu kategorii: bardzo źle, źle, średnio, dobrze, bardzo dobrze. Nie ma liczb, mamy tylko informację o porządku. Pojęcie średniej, na odchyleniu od której szereg miar nierówności się opiera, nie ma wówczas sensu. Średnia zmienia się wraz z przyjętą skalą i łatwo pokazać, że niejednokrotnie zmiana skali powoduje zmianę wniosków co do tego, który rozkład jest bardziej równy. Jest to, oczywiście, niepożądane. W praktyce rządów i organizacji międzynarodowych dojrzewa przekonanie, że należy wychodzić poza PKB per capita w rozumieniu tego, czym jest postęp społeczno-ekonomiczny. Stąd jest duża potrzeba rozwoju teorii pomiaru nierówności, która obejmuje wiele zmiennych i różnego typu.