Liczenie ryb w jeziorze metodą statystyczną i śliczną, choć probabilistyczną
W jeziorze pływa  ryb, ale liczby
ryb, ale liczby  nie znamy. Chcielibyśmy tę liczbę oszacować, nie uciekając się do osuszenia jeziora. Powiedzmy, że dysponujemy wędką, puszką farby i odrobiną wiedzy ze statystyki. Łowimy sobie jedną rybkę po drugiej i wrzucamy z powrotem do jeziora, krzywdy żadnej rybce nie czyniąc. Przed wrzuceniem do wody malujemy rybce kreseczkę na ogonku...
nie znamy. Chcielibyśmy tę liczbę oszacować, nie uciekając się do osuszenia jeziora. Powiedzmy, że dysponujemy wędką, puszką farby i odrobiną wiedzy ze statystyki. Łowimy sobie jedną rybkę po drugiej i wrzucamy z powrotem do jeziora, krzywdy żadnej rybce nie czyniąc. Przed wrzuceniem do wody malujemy rybce kreseczkę na ogonku...

Rybka złowiona powtórnie otrzymuje drugą kreseczkę. Jeśli zdarzy się złowić tę samą rybkę trzeci raz, domalowujemy trzecią kreseczkę i tak dalej. Wyniki naszych połowów zapisujemy w postaci ciągu 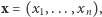 gdzie
gdzie  oznacza liczbę kresek na ogonku
oznacza liczbę kresek na ogonku  -tej złowionej ryby przed wrzuceniem do jeziora. Jeśli, na przykład,
-tej złowionej ryby przed wrzuceniem do jeziora. Jeśli, na przykład,
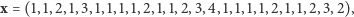 |
to powtarzaliśmy połów 25 razy, złowiliśmy 15 różnych ryb, w tym jedną czterokrotnie, dwie trzykrotnie i trzy dwukrotnie. Jasne, że ciąg  zawiera pewną informację o nieznanej liczbie
zawiera pewną informację o nieznanej liczbie 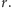 Duża liczba wyrazów ciągu różnych od jedynki (czyli ryb złowionych wielokrotnie) wskazuje na to, że
Duża liczba wyrazów ciągu różnych od jedynki (czyli ryb złowionych wielokrotnie) wskazuje na to, że  jest "prawdopodobnie małe". Postaram się pokazać, jak to intuicyjne rozumowanie uściślić i sformułować wnioski w bardziej konkretnej, ilościowej postaci. Przy okazji zaprezentuję kilka ważnych idei, stojących u podstaw statystyki matematycznej.
jest "prawdopodobnie małe". Postaram się pokazać, jak to intuicyjne rozumowanie uściślić i sformułować wnioski w bardziej konkretnej, ilościowej postaci. Przy okazji zaprezentuję kilka ważnych idei, stojących u podstaw statystyki matematycznej.
Model probabilistyczny
Oczywiście, życie w jeziorze jest bardziej skomplikowane niż matematyka. Żeby coś obliczyć i przeprowadzić porządne rozumowanie, trzeba przyjąć szereg upraszczających założeń.
- Załóżmy, że liczba
 jest niezmienna (ryby nie giną ani nie rozmnażają się).
jest niezmienna (ryby nie giną ani nie rozmnażają się). - Pomiędzy kolejnymi połowami ryby całkowicie "mieszają się". Mówiąc dokładniej, zakładamy, że w każdym kolejnym połowie prawdopodobieństwo wyciągnięcia każdej z ryb jest jednakowe, równe
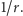
Wyidealizowany model pozwala obliczyć prawdopodobieństwo otrzymania konkretnego wyniku połowu. Niech symbol 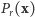 oznacza prawdopodobieństwo otrzymania wyniku
oznacza prawdopodobieństwo otrzymania wyniku 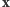 przy założeniu, że nieznana liczba ryb jest równa
przy założeniu, że nieznana liczba ryb jest równa 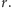 Dla przykładowych danych przytoczonych powyżej mamy
Dla przykładowych danych przytoczonych powyżej mamy
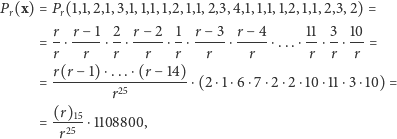 |
gdzie użyliśmy oznaczenia 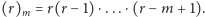 Zauważmy, że 15 jest liczbą jedynek w ciągu
Zauważmy, że 15 jest liczbą jedynek w ciągu  (liczbą różnych złowionych ryb). Łatwo wyjaśnić wyżej napisany wzór, przyglądając się kolejnym ułamkom w drugiej linii:
(liczbą różnych złowionych ryb). Łatwo wyjaśnić wyżej napisany wzór, przyglądając się kolejnym ułamkom w drugiej linii:
- 1.
- Pierwszy wyraz ciągu,
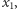 zawsze musi być równy
zawsze musi być równy 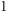 : na początku w jeziorze pływa
: na początku w jeziorze pływa  ryb i wszystkie są nieoznakowane. Pierwszy czynnik jest równy
ryb i wszystkie są nieoznakowane. Pierwszy czynnik jest równy 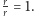
- 2.
- Po pierwszym połowie w jeziorze pływa
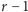 ryb nieoznakowanych i jedna ryba oznaczona jedną kreską. Stąd prawdopodobieństwo otrzymania
ryb nieoznakowanych i jedna ryba oznaczona jedną kreską. Stąd prawdopodobieństwo otrzymania 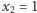 (wyłowienia nowej rybki) wynosi
(wyłowienia nowej rybki) wynosi 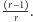
- 3.
- Jeśli
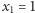 i
i 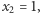 to po drugim połowie w jeziorze pływa
to po drugim połowie w jeziorze pływa  ryb nieoznakowanych i dwie ryby oznaczone jedną kreską. Prawdopodobieństwo otrzymania
ryb nieoznakowanych i dwie ryby oznaczone jedną kreską. Prawdopodobieństwo otrzymania 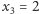 (wyłowienia oznakowanej rybki) wynosi więc
(wyłowienia oznakowanej rybki) wynosi więc 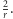
- 4.
- Jeśli
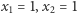 i
i 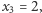 to po trzecim połowie w jeziorze pływa
to po trzecim połowie w jeziorze pływa  ryb nieoznakowanych. Prawdopodobieństwo otrzymania
ryb nieoznakowanych. Prawdopodobieństwo otrzymania 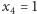 (wyłowienia jednej z tych nieoznakowanych) wynosi
(wyłowienia jednej z tych nieoznakowanych) wynosi 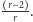
- 5.
- Jeśli
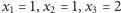 i
i 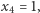 to po czwartym połowie w jeziorze pływa jedna ryba oznaczona dwiema kreskami. Prawdopodobieństwo otrzymania
to po czwartym połowie w jeziorze pływa jedna ryba oznaczona dwiema kreskami. Prawdopodobieństwo otrzymania 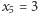 (wyłowienia właśnie tej rybki) wynosi
(wyłowienia właśnie tej rybki) wynosi 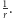
I tak dalej. Proponuję, żeby Czytelnik samodzielnie prześledził pochodzenie dalszych ułamków w naszym wzorze.
Wiarygodność
Wielkość 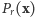 jest funkcją dwóch argumentów:
jest funkcją dwóch argumentów:  jest wynikiem doświadczenia losowego, a
jest wynikiem doświadczenia losowego, a  jest nazywane parametrem. Możliwe są dwa punkty widzenia, charakteryzujące dwie różne dziedziny matematyki.
jest nazywane parametrem. Możliwe są dwa punkty widzenia, charakteryzujące dwie różne dziedziny matematyki.
- Jeśli
 jest ustalone (w domyśle - znane), to
jest ustalone (w domyśle - znane), to 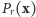 rozważane jako funkcja argumentu
rozważane jako funkcja argumentu  nazywa się prawdopodobieństwem (dokładniej - rozkładem prawdopodonieństwa). To jest punkt widzenia probabilistów.
nazywa się prawdopodobieństwem (dokładniej - rozkładem prawdopodonieństwa). To jest punkt widzenia probabilistów. - Jeśli
 jest ustalone (w domyśle - znane), to
jest ustalone (w domyśle - znane), to 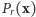 rozważane jako funkcja argumentu
rozważane jako funkcja argumentu  nazywa się wiarygodnością. To jest punkt widzenia statystyków matematycznych.
nazywa się wiarygodnością. To jest punkt widzenia statystyków matematycznych.
W języku potocznym prawdopodobieństwo i wiarygodność są niemal synonimami, ale w naszych rozważaniach różnica między tymi pojęciami jest istotna. Zadanie, które postawiliśmy na początku tego artykułu: oszacowanie nieznanej liczby  na podstawie obserwacji
na podstawie obserwacji 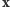 - należy do domeny statystyki.
- należy do domeny statystyki.
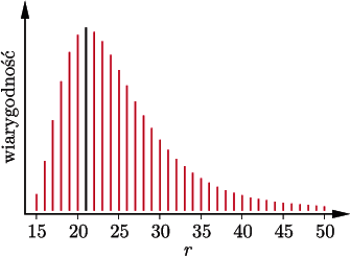
Wykres wiarygodności dla 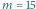 i
i 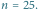 Grubsza czarna linia wskazuje ENW
Grubsza czarna linia wskazuje ENW 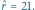
Wykres wiarygodności dla 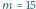 i
i 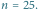 Grubsza czarna linia wskazuje ENW
Grubsza czarna linia wskazuje ENW 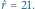
Nasuwa się pomysł, że rozsądnym oszacowaniem parametru  jest taka wartość
jest taka wartość 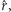 która maksymalizuje wiarygodność
która maksymalizuje wiarygodność
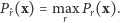 |
Mówimy, że 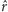 jest estymatorem największej wiarygodności (ENW). Wróćmy do naszego przykładu. Dla ciągu
jest estymatorem największej wiarygodności (ENW). Wróćmy do naszego przykładu. Dla ciągu 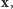 przytoczonego na początku artykułu, wiarygodność osiąga maksimum dla
przytoczonego na początku artykułu, wiarygodność osiąga maksimum dla 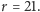 Chciałoby się powiedzieć, że "21 jest najbardziej prawdopodobną liczbą ryb". Ale, ale! Nie wolno tak mówić! W naszym modelu
Chciałoby się powiedzieć, że "21 jest najbardziej prawdopodobną liczbą ryb". Ale, ale! Nie wolno tak mówić! W naszym modelu  nie jest wynikiem jakiegoś doświadczenia losowego, a więc nie można mówić o "prawdopodobieństwie otrzymania
nie jest wynikiem jakiegoś doświadczenia losowego, a więc nie można mówić o "prawdopodobieństwie otrzymania  ". Wobec tego statystycy mówią: "21 jest najbardziej wiarygodną liczbą ryb". Jest to wybieg językowy, który ukrywa dość zawiłą i niewygodną interpretację ENW. "Najbardziej prawdopodobny" po prostu znaczy "najczęściej pojawiający się w wielokrotnych powtórzeniach doświadczenia losowego". Ale co znaczy "najbardziej wiarygodny"?
". Wobec tego statystycy mówią: "21 jest najbardziej wiarygodną liczbą ryb". Jest to wybieg językowy, który ukrywa dość zawiłą i niewygodną interpretację ENW. "Najbardziej prawdopodobny" po prostu znaczy "najczęściej pojawiający się w wielokrotnych powtórzeniach doświadczenia losowego". Ale co znaczy "najbardziej wiarygodny"?
- ENW to jest taka wartość parametru, dla której, jeśliby wielokrotnie powtarzać doświadczenie losowe, to częściej otrzymywalibyśmy taki wynik, jaki w rzeczywistości otrzymaliśmy, w porównaniu z innymi możliwymi wartościami parametru.
Dostateczność
Jak wynika z naszych dotychczasowych rozważań, wzór na wiarygodność w naszym rybackim zadaniu ma postać
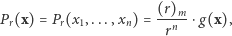 |
gdzie 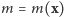 jest liczbą jedynek w ciągu
jest liczbą jedynek w ciągu 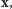 zaś
zaś 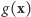 jest funkcją
jest funkcją 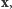 niezależącą od nieznanego
niezależącą od nieznanego 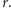 Co prawda, ta funkcja jest raczej skomplikowana, ale nie będzie nam potrzebna! Zauważmy, że ENW możemy obliczyć, maksymalizując wyrażenie
Co prawda, ta funkcja jest raczej skomplikowana, ale nie będzie nam potrzebna! Zauważmy, że ENW możemy obliczyć, maksymalizując wyrażenie 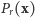 z pominiętym czynnikiem
z pominiętym czynnikiem 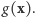 W rezultacie otrzymane oszacowanie
W rezultacie otrzymane oszacowanie 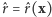 zależy tylko od
zależy tylko od 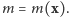 Okazuje się, że tylko
Okazuje się, że tylko 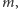 liczba jedynek, zawiera informację o nieznanej liczbie
liczba jedynek, zawiera informację o nieznanej liczbie 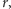 wszystkie inne wielkości związane z wektorem
wszystkie inne wielkości związane z wektorem 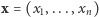 są nieistotne! Mówimy, że
są nieistotne! Mówimy, że 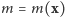 jest statystyką dostateczną. Następujące piękne rozumowanie przekona nas, że tak jest naprawdę. Ponieważ mamy
jest statystyką dostateczną. Następujące piękne rozumowanie przekona nas, że tak jest naprawdę. Ponieważ mamy
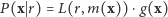 |
dla pewnej funkcji 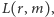 to zgodnie z definicją prawdopodobieństwa warunkowego
to zgodnie z definicją prawdopodobieństwa warunkowego
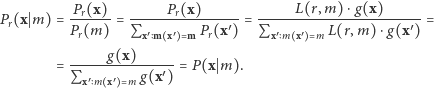
Prawdopodobieństwo warunkowe 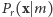 nie zależy od
nie zależy od 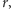 dlatego na końcu opuściliśmy indeks
dlatego na końcu opuściliśmy indeks 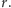 Przeprowadźmy następujące doświadczenie myślowe. Wyobraźmy sobie, że po dokonaniu połowu zapamiętaliśmy liczbę
Przeprowadźmy następujące doświadczenie myślowe. Wyobraźmy sobie, że po dokonaniu połowu zapamiętaliśmy liczbę 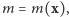 a potem zgubiliśmy kartkę z zapisanym wektorem
a potem zgubiliśmy kartkę z zapisanym wektorem 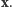 Możemy odtworzyć zgubiony wynik doświadczenia, znając tylko
Możemy odtworzyć zgubiony wynik doświadczenia, znając tylko 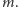 Wylosujemy mianowicie fikcyjny wynik
Wylosujemy mianowicie fikcyjny wynik 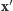 z prawdopodobieństwem
z prawdopodobieństwem 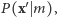 bo do tego nie jest potrzebna znajomość
bo do tego nie jest potrzebna znajomość 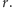 Chwila zastanowienia prowadzi do wniosku, że
Chwila zastanowienia prowadzi do wniosku, że 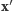 ma ten sam rozkład prawdopodobieństwa co
ma ten sam rozkład prawdopodobieństwa co 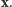 Skoro sposób naszego losowania nie zależał już od
Skoro sposób naszego losowania nie zależał już od 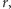 to uzyskany wynik nie mógł ze sobą nieść żadnej dodatkowej informacji o
to uzyskany wynik nie mógł ze sobą nieść żadnej dodatkowej informacji o 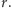 W tej sytuacji cała nasza wiedza o tym parametrze musi być "ukryta" w liczbie
W tej sytuacji cała nasza wiedza o tym parametrze musi być "ukryta" w liczbie 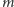 !
!
Na zakończenie dodam, że tytuł tego artykułu zapożyczyłem z pięknego opowiadania Stanisława Lema O królewiczu Ferrycym i królewnie Krystali - opowieść z cyklu Dzieła Cyfrotikon, czyli o dewijacyach, superfiksacyach, a waryacyach serdecznych.