Turing kontra spamboty

Czy komputery potrafią myśleć? Ta kwestia nurtuje informatyków od ponad pół wieku. W 1950 roku angielski matematyk Alan Turing zadał podobne, ale bardziej precyzyjne pytanie. A mianowicie, czy komputer (lub program komputerowy) jest w stanie przekonać człowieka, że sam również jest istotą ludzką. Turing zaproponował wtedy następujący test (który dziś, na jego cześć, zwany jest testem Turinga). Jeśli człowiek-sędzia podczas rozmowy prowadzonej w języku naturalnym (ale za pośrednictwem pisma) równocześnie z człowiekiem oraz z programem komputerowym nie będzie w stanie stwierdzić, który z interlokutorów jest który – to taki program zalicza test Turinga.
Choć od jego sformułowania minęło ponad sześćdziesiąt lat, to jak dotąd żadnemu programowi komputerowemu nie udało się przejść testu Turinga i nic nie zapowiada, że w najbliższej przyszłości miałoby się to zmienić. Pojawiające się co jakiś czas doniesienia, że było blisko (jak w 2001 roku w przypadku programu Cleverbot), należy traktować z dużą dozą sceptycyzmu.
Ironią może być więc fakt, że pomimo tego, iż komputery nie wypadają najlepiej jako ich uczestnicy, to podobnego rodzaju testy organizuje się na masową skalę z komputerami w roli sędziów. Zapewne każdy Czytelnik, serfując po Internecie, nie raz brał udział w teście, podczas którego musiał przekonać program komputerowy o swoim człowieczeństwie. Mogło to być przy okazji zakładania konta poczty elektronicznej, wypełniania formularza w sklepie internetowym, czy też umieszczania komentarza na forum. Takie odwrócone testy Turinga są powszechne tam, gdzie właściciele stron internetowych chcą odsiać aktywność spambotów (czyli takich programów komputerowych, które na masową skalę zasypują sieć spamem).
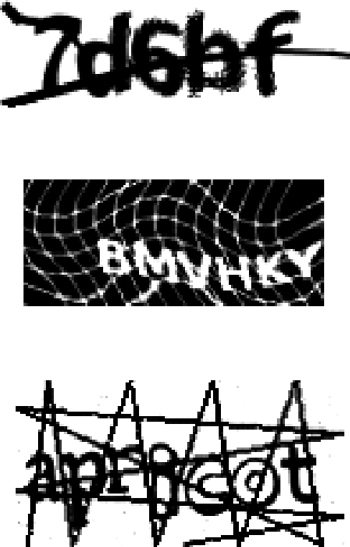
Rys. 1 Przykładowe obrazki generowane przez różne implementacje CAPTCHA.
A wszystko zaczęło się w 2000 roku, kiedy to Luis von Ahn i trzech innych naukowców z Carnegie Mellon University ukuło termin CAPTCHA (ang. Completely Automated Public Turing test to tell Computers and Humans Apart), oznaczający program komputerowy, który generuje test w zamierzeniu łatwy do zaliczenia przez człowieka, ale trudny do zaliczenia przez maszynę. Najpopularniejszy test polega na przedstawieniu egzaminowanemu obrazka zawierającego zniekształcony napis, który należy odczytać i wprowadzić do formularza (Rys. 1). Dziś nietrudno natknąć się na podobnego rodzaju obrazki, a w sieci trwa batalia między dwiema grupami programistów – tymi, którzy tworzą nowe implementacje CAPTCHA, i tymi, którzy tworzą doskonalsze spamboty do ich łamania.
Jest jednak sporo argumentów przemawiających przeciwko stosowaniu CAPTCHA. Przede wszystkim jest to metoda dość uciążliwa dla użytkowników (zwłaszcza jeśli jest wymagana przy częstych czynnościach jak np. wpisanie komentarza). Może być też nie do przejścia dla niektórych ludzi (np. niewidomi posługujący się drukarkami Braille’a nie zobaczą obrazka).
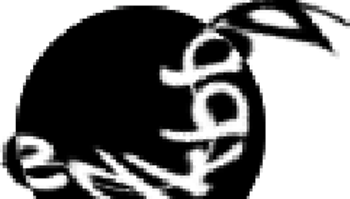
Rys. 2 Zbyt zniekształcona CAPTCHA z poczty na stronie internetowej wp.pl.
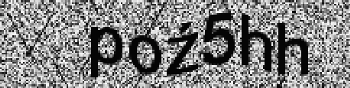
Rys. 3 CAPTCHA prezentowana podczas tworzenia konta na poczcie onet.pl, która nie sprawi trudności spambotom.
Poza tym skonstruowanie dobrego testu nie jest wcale łatwe, a źle skonstruowany test będzie więcej niż bezużyteczny. Jeśli algorytm generujący obrazki zbytnio zniekształci napis, to test taki stanie się zbyt trudny nawet dla ludzi (Rys. 2). Z drugiej strony komputery dobrze radzą sobie z usuwaniem szumu z obrazu i klasyfikowaniem pojedynczych liter, a trudność sprawia im podział słowa na litery. W związku z tym implementacje, które nie łączą liter, skazane są na niepowodzenie – napisanie programu, które je rozwiązuje, nie będzie trudne (Rys. 3).
Przez lata pojawiło się wiele konkurencyjnych pomysłów, które w zamierzeniu
miały dać CAPTCHA idealną. Jednym z nich jest prezentowanie prostych
pytań typu: „ile jest
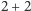 ” lub „kto jest najlepszym przyjacielem
człowieka”. Problem z tym rozwiązaniem jest taki, że spamboty mogą wpisać
to pytanie do wyszukiwarki Google i zanalizować otrzymane wyniki. Innym
pomysłem jest zaprezentowanie egzaminowanemu kilku obrazków i polecenie,
by zaznaczył on te, na których znajduje się np. kot. Tutaj kłopot jest taki, że
takie rozwiązania wymagają stworzenia dużej bazy danych pytań (co jest
trudniejsze niż deformacja losowego napisu). W przeciwnym przypadku
pytania zaczną się powtarzać, więc po pewnym czasie spamboty po prostu
zgadną prawidłową odpowiedź.
” lub „kto jest najlepszym przyjacielem
człowieka”. Problem z tym rozwiązaniem jest taki, że spamboty mogą wpisać
to pytanie do wyszukiwarki Google i zanalizować otrzymane wyniki. Innym
pomysłem jest zaprezentowanie egzaminowanemu kilku obrazków i polecenie,
by zaznaczył on te, na których znajduje się np. kot. Tutaj kłopot jest taki, że
takie rozwiązania wymagają stworzenia dużej bazy danych pytań (co jest
trudniejsze niż deformacja losowego napisu). W przeciwnym przypadku
pytania zaczną się powtarzać, więc po pewnym czasie spamboty po prostu
zgadną prawidłową odpowiedź.
Kolejnym argumentem przeciwników CAPTCHA jest to, że marnuje ona mnóstwo energii ludzkiej. Jak podają profesorowie z Carnegie Mellon, dziennie rozwiązywanych jest około 200 milionów CAPTCHA, co przy średnim czasie dziesięciu sekund na obrazek daje pół miliona godzin pracy dziennie. Luis von Ahn postanowił przeciwdziałać temu marnotrawstwu. Co ciekawe, jego pomysł polegał nie na wyeliminowaniu testów, ale na sprawieniu, by przy okazji ich rozwiązywania ludzie wykonywali pożyteczną pracę, której nie umieją wykonać komputery. Tak w roku 2008 powstał system reCAPTCHA, który pomaga digitalizować książki.

Rys. 4 Dwa słowa reCAPTCHA.
Pomysł jest następujący: transformacja papierowej książki na tekst cyfrowy wymaga najpierw zeskanowania poszczególnych stron (co można zrobić mniej lub bardziej maszynowo), a następnie przepuszczenia ich przez oprogramowanie do rozpoznawania tekstu (OCR, ang. Optical Character Recognition). Dzięki zaawansowanym algorytmom znacząca część tekstu jest rozpoznawana poprawnie, ale niektóre słowa (zwłaszcza w starszych książkach) są dla nich zbyt zniekształcone. Takie słowa, których nie udało się rozpoznać automatycznie, trafiają do bazy słów reCAPTCHA. Podczas testu użytkownikowi przedstawiane są do przepisania dwa słowa: dla jednego z tych słów system zna poprawną odpowiedź (spełnia ono więc taką samą kontrolną funkcję jak w systemie CAPTCHA), a drugie słowo pochodzi z bazy słów nierozpoznanych przez OCR (z tym że kolejność tych dwóch słów jest losowa). Jeśli użytkownik poprawnie wpisze słowo kontrolne, to test jest zaliczany, a do bazy dopisywane jest potencjalne rozwiązanie nieznanego słowa. Jeśli kilku użytkowników w ten sam sposób odczyta nieznane słowo, to system uznaje je za rozpoznane.