Co to jest?
Jak to działa?
Miara ważności
Czy zastanawiałeś się, drogi Czytelniku, dlaczego wyszukiwarka wyświetla adresy stron będących odpowiedzią na Twoje zapytanie właśnie w takiej, a nie innej kolejności?

Zanim zacząłem pisać tę krótką notkę, zażądałem od wyszukiwarki
google.pl odpowiedzi na pytanie „matematyka”. Pierwszych
pięć adresów do stron, które otrzymałem w odpowiedzi,
to
(1) www.matematyka.org,
(2) www.matematyka.pl,
(3) www.math.edu.pl,
(4) pl.wikipedia.org/wiki/Matematyka,
(5) www.freewebs.com/podmatematyka.
Google „pochwalił się”, że wybrał je spośród 2 810 000 kandydatów. Dlaczego właśnie te uznano za najważniejsze? Jaka jest miara ważności strony? Okazuje się, że podstawą analizy ważności stron w Google jest analiza połączeń w grafie Internetu. Graf Internetu jest grafem skierowanym, w którym węzłami są strony, a krawędzie odpowiadają dowiązaniom pomiędzy stronami – strona zawierająca adres internetowy innej strony jest początkiem krawędzi, a strona o danym adresie jej końcem. Czy można na podstawie grafu Internetu powiedzieć, które strony są ważniejsze, a które mniej? Strona ważna to strona interesująca. Strona interesująca to taka, do której łatwo dotrzeć, ponieważ wiele innych stron na nią wskazuje. Na dodatek wiele spośród stron wskazujących na ważną stronę też jest ważnych i interesujących, itd. Larry Page i Sergey Brin, twórcy Google, wyrazili to matematycznie w następujący sposób.
Załóżmy, że mamy
 stron
stron
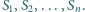 Niech
Niech
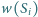 będzie liczbą rzeczywistą dodatnią mierzącą ważność strony
będzie liczbą rzeczywistą dodatnią mierzącą ważność strony
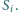 Wówczas żądamy, żeby
Wówczas żądamy, żeby

gdzie
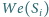 jest zbiorem stron zawierających adres strony
jest zbiorem stron zawierających adres strony
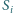 (czyli zbiórem początków krawędzi prowadzących do
(czyli zbiórem początków krawędzi prowadzących do
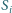 ), zaś
), zaś
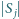 jest liczbą odnośników (krawędzi) wychodzących ze strony
jest liczbą odnośników (krawędzi) wychodzących ze strony
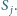
Powyższy wzór oznacza, że ważność strony mierzy się ważnością stron
na nią wskazujących. Jeżeli przyjmiemy na początek, że wszystkie strony są
jednakowo ważne i dla każdej z nich
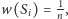 gdzie
gdzie
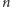 to liczba
wszystkich stron, to ważność stron można obliczyć za pomocą następującej
metody iteracyjnej:
to liczba
wszystkich stron, to ważność stron można obliczyć za pomocą następującej
metody iteracyjnej:
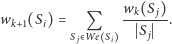
Na powyższy proces można spojrzeć jak na błądzenie losowe po grafie Internetu. Rozpoczynamy z dowolnej strony, a następnie z każdej oglądanej strony ruszamy losowo do jednej ze stron, do których adresy umieszczono na tej stronie. Jeśli nasz proces będziemy powtarzali bardzo długo, to pewne ze stron będziemy oglądali częściej niż inne. Strony oglądane częściej są ważniejsze.
Niestety, może się zdarzyć, że serfując po stronach, natrafimy na takie, z których nie ma wyjścia, np. strony zawierające zdjęcia. W takim przypadku zakładamy, że w następnym kroku wybierzemy losowo dowolną ze stron w Internecie. Teraz nasz proces iteracyjny wygląda następująco:
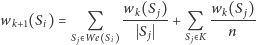
gdzie
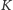 oznacza zbiór wszystkich stron końcowych, czyli takich, które
nie zawierają dowiązań do żadnych innych stron. Jesteśmy już blisko
algorytmu Google ustalania miary ważności stron.
oznacza zbiór wszystkich stron końcowych, czyli takich, które
nie zawierają dowiązań do żadnych innych stron. Jesteśmy już blisko
algorytmu Google ustalania miary ważności stron.
Brin i Page obserwując zachowanie użytkowników Internetu, zauważyli,
że czasami porzucają oni bieżące przeszukiwanie i rozpoczynają nowe od
(losowo) wybranej strony. Dlatego zmodyfikowali swój proces iteracyjny,
wprowadzając parametr
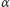 o wartości z przedziału
o wartości z przedziału
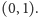
W każdej iteracji z prawdopodobieństwem
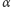 aktualne przeszukiwanie
jest kontynuowane, natomiast z prawdopodobieństwem
aktualne przeszukiwanie
jest kontynuowane, natomiast z prawdopodobieństwem
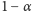 rozpoczynane jest nowe przeszukiwanie. Ostatecznie postać każdej iteracji jest
następująca:
rozpoczynane jest nowe przeszukiwanie. Ostatecznie postać każdej iteracji jest
następująca:
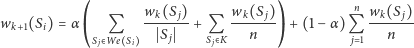
Bardziej doświadczeni Czytelnicy pewnie już spostrzegli, że nasz proces iteracyjny jest procesem stochastycznym zbieżnym do stacjonarnego rozkładu prawdopodobieństwa. Celem kolejnych modyfikacji procesu było zapewnienie właśnie takiej zbieżności. Końcowy rozkład prawdopodobieństwa odpowiada mierze ważności stron.
Oczywiście, jest jeszcze wiele pytań, które pozostają bez odpowiedzi: Jak
szybko powyższy proces zbiega do końcowego rozkładu? Jak dobierać
parametr
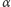 ? W jaki sposób przeprowadzać obliczenia na grafie
Internetu, który w chwili obecnej liczy blisko 100 000 000 domen?
? W jaki sposób przeprowadzać obliczenia na grafie
Internetu, który w chwili obecnej liczy blisko 100 000 000 domen?
Odpowiedzi na te pytania to już inna historia. Wszystkich zainteresowanych odsyłam do wspaniałej książki autorstwa Amy N. Langville i Carla D. Meyera, Google’s PageRank and Beyond: The Science of Search Engine Rankings.