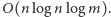Informatyczny kącik olimpijski
Obcy
W tym odcinku prezentujemy najtrudniejsze zadanie z zeszłorocznej Międzynarodowej Olimpiady Informatycznej.
Nad obcą planetą ma przelecieć statek badawczy, którego załoga chce sfotografować interesujące obszary planety. Na powierzchnię planety naniesiono kwadratową siatkę o rozmiarach 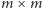 podzieloną na pola rozmiaru
podzieloną na pola rozmiaru 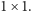 Statek badawczy będzie poruszać się nad główną przekątną tej siatki, to znaczy od lewego górnego do prawego dolnego rogu. Każde wykonane zdjęcie obejmie kwadratowy obszar, który składa się z pewnej liczby całych pól i którego przekątna leży na głównej przekątnej całej siatki. Na potrzeby opisu każdy taki kwadratowy obszar nazwiemy poprawnym kwadratem.
Statek badawczy będzie poruszać się nad główną przekątną tej siatki, to znaczy od lewego górnego do prawego dolnego rogu. Każde wykonane zdjęcie obejmie kwadratowy obszar, który składa się z pewnej liczby całych pól i którego przekątna leży na głównej przekątnej całej siatki. Na potrzeby opisu każdy taki kwadratowy obszar nazwiemy poprawnym kwadratem.
Danych jest  interesujących pól. Naszym celem jest tak zaplanować wykonanie
interesujących pól. Naszym celem jest tak zaplanować wykonanie 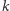 zdjęć, by każde interesujące pole zostało sfotografowane. Dodatkowo naszym celem jest zminimalizowanie kosztu rozwiązania, za który przyjmujemy łączną liczbę sfotografowanych pól, przy czym wielokrotnie sfotografowane pola liczymy tylko raz. Wartości
zdjęć, by każde interesujące pole zostało sfotografowane. Dodatkowo naszym celem jest zminimalizowanie kosztu rozwiązania, za który przyjmujemy łączną liczbę sfotografowanych pól, przy czym wielokrotnie sfotografowane pola liczymy tylko raz. Wartości 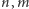 i
i 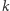 są rzędu
są rzędu 
Zacznijmy od prostego spostrzeżenia. Rozważmy pewne interesujące pole  i najmniejszy poprawny kwadrat
i najmniejszy poprawny kwadrat 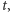 który je zawiera. Wówczas poprawne kwadraty zawierające pole
który je zawiera. Wówczas poprawne kwadraty zawierające pole  to dokładnie te, których główna przekątna zawiera główną przekątną
to dokładnie te, których główna przekątna zawiera główną przekątną 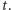
Dzięki takiemu spojrzeniu nasz problem staje się poniekąd jednowymiarowy. Każde interesujące pole wyznacza pewien przedział na prostej zawierającej główną przekątną siatki. Łącznie danych jest  takich przedziałów. Naszym celem jest zaznaczenie
takich przedziałów. Naszym celem jest zaznaczenie 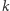 odcinków na tej prostej (każdy odcinek wyznacza jeden sfotografowany obszar) w taki sposób, by każdy przedział był w pełni zawarty w jednym z odcinków. Technicznie rzecz biorąc, przedział i odcinek na prostej to to samo, jednak dla jednoznaczności dane odcinki będziemy nazywać przedziałami. Nieco trudniej wyrazić w tym języku wartość, którą powinniśmy zminimalizować - do tego problemu wrócimy za chwilę.
odcinków na tej prostej (każdy odcinek wyznacza jeden sfotografowany obszar) w taki sposób, by każdy przedział był w pełni zawarty w jednym z odcinków. Technicznie rzecz biorąc, przedział i odcinek na prostej to to samo, jednak dla jednoznaczności dane odcinki będziemy nazywać przedziałami. Nieco trudniej wyrazić w tym języku wartość, którą powinniśmy zminimalizować - do tego problemu wrócimy za chwilę.
Zauważmy teraz, że jeśli jeden z danych przedziałów  zawiera się w innym przedziale
zawiera się w innym przedziale 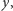 przedział
przedział 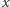 możemy usunąć z danych wejściowych. Usuwamy więc zbędne przedziały, a następnie sortujemy pozostałe przedziały rosnąco względem ich lewych końców. Dzięki wykonaniu pierwszego kroku przedziały będą posortowane również względem swoich prawych końców.
możemy usunąć z danych wejściowych. Usuwamy więc zbędne przedziały, a następnie sortujemy pozostałe przedziały rosnąco względem ich lewych końców. Dzięki wykonaniu pierwszego kroku przedziały będą posortowane również względem swoich prawych końców.
Teraz czas na pierwsze rozwiązanie zadania. Oznaczmy lewe końce przedziałów przez 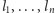 a prawe przez
a prawe przez 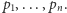 Skorzystamy z metody programowania dynamicznego. Oznaczmy przez
Skorzystamy z metody programowania dynamicznego. Oznaczmy przez ![d[i][ j]](/math/temat/informatyka/algorytmy/2017/03/27/Obcy/3x-897187841e0cc03c3b39f37ee49772493089d124-im-33,33,33-FF,FF,FF.gif) minimalny koszt pokrycia pierwszych
minimalny koszt pokrycia pierwszych 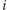 przedziałów za pomocą
przedziałów za pomocą 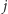 odcinków.
odcinków.
Zastanówmy się, jak skonstruowane jest rozwiązanie odpowiadające wartości ![|d[i][ j].](/math/temat/informatyka/algorytmy/2017/03/27/Obcy/1x-79a9eca8417b2f7a324133e7b28152a3e90d6962-im-33,33,33-FF,FF,FF.gif) Pokrywamy
Pokrywamy 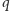 pierwszych przedziałów (dla pewnego
pierwszych przedziałów (dla pewnego 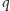 ) za pomocą
) za pomocą 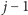 odcinków, a przedziały od
odcinków, a przedziały od 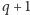 do
do 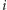 musimy pokryć osobnym odcinkiem. Wartość
musimy pokryć osobnym odcinkiem. Wartość 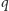 jest, oczywiście, dobrana tak, by zminimalizować koszt. Stąd, dla
jest, oczywiście, dobrana tak, by zminimalizować koszt. Stąd, dla 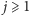 otrzymujemy
otrzymujemy
![2 2 d[i][ j] = m0iDnq@id[s][ j− 1]+ (pi− lq+1) − max(0, (pq − lq+1)),](/math/temat/informatyka/algorytmy/2017/03/27/Obcy/9x-79a9eca8417b2f7a324133e7b28152a3e90d6962-dm-33,33,33-FF,FF,FF.gif)
gdzie ostatni składnik odpowiada za odjęcie pól sfotografowanych wielokrotnie. Poza tym przyjmujemy ![d[0][0] = 0, d[i][0] = ∞](/math/temat/informatyka/algorytmy/2017/03/27/Obcy/10x-79a9eca8417b2f7a324133e7b28152a3e90d6962-im-33,33,33-FF,FF,FF.gif) dla
dla 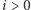 oraz
oraz 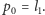 Za pomocą tego wzoru możemy wyznaczyć wartość
Za pomocą tego wzoru możemy wyznaczyć wartość ![d[n][k]](/math/temat/informatyka/algorytmy/2017/03/27/Obcy/13x-79a9eca8417b2f7a324133e7b28152a3e90d6962-im-33,33,33-FF,FF,FF.gif) i gotowe. Problem w tym, że to rozwiązanie działa zdecydowanie zbyt wolno. W szczególności, jeśli minimum obliczać będziemy w czasie liniowym od
i gotowe. Problem w tym, że to rozwiązanie działa zdecydowanie zbyt wolno. W szczególności, jeśli minimum obliczać będziemy w czasie liniowym od 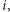 to otrzymamy rozwiązanie działające w czasie
to otrzymamy rozwiązanie działające w czasie 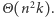
Obliczanie minimum w podanym wzorze można jednak zrealizować znacznie szybciej. Rozważmy następujący problem. Dany jest zbiór funkcji liniowych, w którym 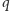 -ta funkcja opisana jest wzorem
-ta funkcja opisana jest wzorem 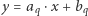 (wartości
(wartości 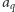 oraz
oraz 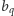 są dane). Naszym zadaniem jest zbudowanie struktury danych, która pozwoli obliczać minimum tych funkcji w każdym punkcie. Innymi słowy, zadaniem struktury danych jest obliczenie wartości funkcji
są dane). Naszym zadaniem jest zbudowanie struktury danych, która pozwoli obliczać minimum tych funkcji w każdym punkcie. Innymi słowy, zadaniem struktury danych jest obliczenie wartości funkcji 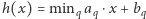 dla podanej wartości
dla podanej wartości 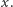 Ponadto struktura powinna pozwalać na dodawanie nowych funkcji do zbioru.
Ponadto struktura powinna pozwalać na dodawanie nowych funkcji do zbioru.

Rys. 1
Zastanówmy się najpierw, jakie dane powinna przechowywać struktura danych. Spójrzmy na rysunek 1, gdzie przedstawiono kilka przykładowych funkcji i wyznaczoną przez nie funkcję 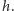 Wykres funkcji
Wykres funkcji 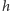 składa się z pewnej liczby fragmentów, gdzie każdy fragment to odcinek, półprosta lub prosta (w przypadku, gdy mamy tylko jeden fragment). Każdy fragment leży na jednej z prostych ze zbioru: kolejne (od lewej) fragmenty leżą na prostych o coraz mniejszych wartościach współczynnika
składa się z pewnej liczby fragmentów, gdzie każdy fragment to odcinek, półprosta lub prosta (w przypadku, gdy mamy tylko jeden fragment). Każdy fragment leży na jednej z prostych ze zbioru: kolejne (od lewej) fragmenty leżą na prostych o coraz mniejszych wartościach współczynnika 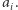
Aby reprezentować wykres funkcji 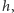 struktura danych pamięta listę
struktura danych pamięta listę 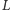 kolejnych fragmentów (od lewej do prawej). Naturalny sposób reprezentacji polega na opisaniu każdego fragmentu przez punkty na jego końcach, jednak nie polecamy tego podejścia. Wymaga ono specjalnego traktowania fragmentów będących prostymi i półprostymi oraz odpowiedniej reprezentacji liczb wymiernych. Znacznie łatwiej pamiętać listę prostych
kolejnych fragmentów (od lewej do prawej). Naturalny sposób reprezentacji polega na opisaniu każdego fragmentu przez punkty na jego końcach, jednak nie polecamy tego podejścia. Wymaga ono specjalnego traktowania fragmentów będących prostymi i półprostymi oraz odpowiedniej reprezentacji liczb wymiernych. Znacznie łatwiej pamiętać listę prostych 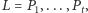 które wyznaczają kolejne fragmenty tworzące wykres
które wyznaczają kolejne fragmenty tworzące wykres 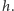 Każdą prostą reprezentujemy tutaj przez parę liczb
Każdą prostą reprezentujemy tutaj przez parę liczb 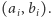 Mówiąc konkretniej, lista
Mówiąc konkretniej, lista 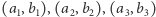 oznacza, że wykres funkcji
oznacza, że wykres funkcji 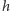 przebiega najpierw po prostej
przebiega najpierw po prostej 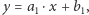 następnie po
następnie po 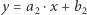 i wreszcie po
i wreszcie po 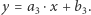 Co ciekawe, nie musimy tu wcale pamiętać, na jakim przedziale wykres
Co ciekawe, nie musimy tu wcale pamiętać, na jakim przedziale wykres 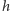 pokrywa się z każdą z prostych - to możemy obliczać w miarę potrzeby. Korzystamy tu z faktu, że prosta
pokrywa się z każdą z prostych - to możemy obliczać w miarę potrzeby. Korzystamy tu z faktu, że prosta 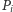 pokrywa się z wykresem
pokrywa się z wykresem 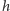 od punktu, w którym
od punktu, w którym 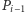 przecina się z
przecina się z 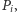 aż do punktu, w którym
aż do punktu, w którym 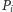 przecina się z
przecina się z 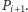
Aby obliczyć wartość 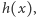 skorzystamy z wyszukiwania binarnego elementów listy
skorzystamy z wyszukiwania binarnego elementów listy 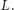 Chcemy na tej liście znaleźć prostą
Chcemy na tej liście znaleźć prostą 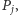 która w punkcie
która w punkcie  pokrywa się z wykresem funkcji
pokrywa się z wykresem funkcji 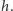 Aby zrealizować wyszukiwanie binarne, musimy umieć dla każdej prostej
Aby zrealizować wyszukiwanie binarne, musimy umieć dla każdej prostej 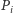 szybko stwierdzić, czy jej indeks
szybko stwierdzić, czy jej indeks 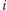 jest mniejszy, równy, czy też większy od
jest mniejszy, równy, czy też większy od 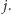 To potrafimy rozstrzygnąć bez trudu. Jeśli, na przykład,
To potrafimy rozstrzygnąć bez trudu. Jeśli, na przykład, 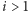 oraz pierwsza współrzędna punktu przecięcia prostych
oraz pierwsza współrzędna punktu przecięcia prostych 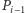 i
i 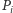 jest większa od
jest większa od 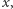 wnioskujemy, że
wnioskujemy, że 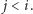 Analogicznie możemy rozpoznać pozostałe przypadki. Co ważne, przy naszej reprezentacji potrzebne warunki możemy sprawdzić, wykonując jedynie operacje na liczbach całkowitych, o ile tylko odpowiednio przekształcimy niezbędne wzory. Tym samym obliczenie wartości
Analogicznie możemy rozpoznać pozostałe przypadki. Co ważne, przy naszej reprezentacji potrzebne warunki możemy sprawdzić, wykonując jedynie operacje na liczbach całkowitych, o ile tylko odpowiednio przekształcimy niezbędne wzory. Tym samym obliczenie wartości 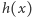 zrealizować możemy w czasie
zrealizować możemy w czasie 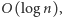 gdzie
gdzie 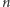 to liczba funkcji liniowych w zbiorze.
to liczba funkcji liniowych w zbiorze.
Pozostaje powiedzieć, jak dodawać nowe proste do zbioru. Rozważymy tu nieco uproszczony przypadek, gdy rozpoczynamy od pustego zbioru prostych i następnie dodajemy proste o coraz mniejszych współczynnikach kierunkowych, tj. kolejno dodawane proste są "coraz bardziej pochylone w prawo". Jak się później okaże, taką własność będą miały proste, które będziemy dodawać do zbioru, gdy wykorzystamy strukturę danych do rozwiązania naszego zadania.
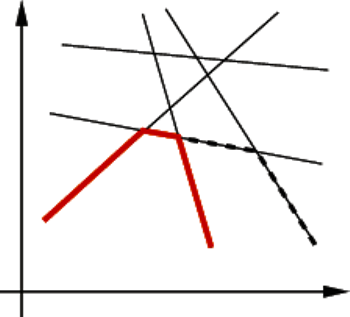
Rys. 2
Spójrzmy na rysunek 2, który pokazuje, jak zmienia się wykres funkcji 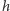 po dodaniu nowej prostej do zbioru. Aby zaktualizować listę
po dodaniu nowej prostej do zbioru. Aby zaktualizować listę 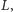 musimy najpierw usunąć pewną liczbę prostych z końca listy
musimy najpierw usunąć pewną liczbę prostych z końca listy 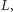 a następnie dopisać na jej końcu właśnie dodaną prostą.
a następnie dopisać na jej końcu właśnie dodaną prostą.

Rys. 3
Usuwanie prostych łatwo zrealizować w pętli, powtarzając następujący krok. Jeśli punkt przecięcia dodawanej prostej z przedostatnią prostą na liście 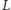 leży na lewo od punktu przecięcia przedostatniej i ostatniej prostej z listy
leży na lewo od punktu przecięcia przedostatniej i ostatniej prostej z listy 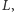 usuwamy ostatnią prostą z listy
usuwamy ostatnią prostą z listy 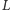 (patrz rysunek 3). W przeciwnym razie kończymy pętlę i dopisujemy dodawaną prostą na końcu listy
(patrz rysunek 3). W przeciwnym razie kończymy pętlę i dopisujemy dodawaną prostą na końcu listy 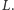 Dodanie jednej prostej do zbioru może spowodować usunięcie wielu prostych z listy
Dodanie jednej prostej do zbioru może spowodować usunięcie wielu prostych z listy 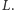 Niemniej jednak każda prosta zostaje dopisana do listy
Niemniej jednak każda prosta zostaje dopisana do listy 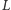 raz i może być z niej usunięta co najwyżej jednokrotnie. Wobec tego łączny czas potrzebny na aktualizacje listy
raz i może być z niej usunięta co najwyżej jednokrotnie. Wobec tego łączny czas potrzebny na aktualizacje listy 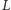 w trakcie dodawania
w trakcie dodawania 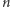 prostych do początkowo pustego zbioru wynosi
prostych do początkowo pustego zbioru wynosi 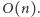 Na tym kończymy opis pomocniczej struktury danych.
Na tym kończymy opis pomocniczej struktury danych.
Pokażemy teraz, jak wykorzystać powyższą strukturę danych do rozwiązania oryginalnego zadania. Problematycznym elementem wzoru na ![d[i][j] |](/math/temat/informatyka/algorytmy/2017/03/27/Obcy/1x-88e1dac2a0899b153204ffe5b0fd26bebd3cb21d-im-33,33,33-FF,FF,FF.gif) może się wydawać funkcja kwadratowa, jednak to tylko pozorna trudność. Zmieńmy nieco wzór na
może się wydawać funkcja kwadratowa, jednak to tylko pozorna trudność. Zmieńmy nieco wzór na ![d[i][ j]](/math/temat/informatyka/algorytmy/2017/03/27/Obcy/2x-88e1dac2a0899b153204ffe5b0fd26bebd3cb21d-im-33,33,33-FF,FF,FF.gif) :
:

Oznaczmy 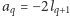 oraz
oraz
![b = d[q][ j −1]+ l2 − (max(0, (p − l )))2. q q+1 q q+1](/math/temat/informatyka/algorytmy/2017/03/27/Obcy/5x-88e1dac2a0899b153204ffe5b0fd26bebd3cb21d-dm-33,33,33-FF,FF,FF.gif)
Przy takich oznaczeniach mamy
![2 d[i][ j] = pi + m0iDnq@iaq⋅pi + bq.](/math/temat/informatyka/algorytmy/2017/03/27/Obcy/6x-88e1dac2a0899b153204ffe5b0fd26bebd3cb21d-dm-33,33,33-FF,FF,FF.gif)
co pozwala nam skorzystać z opisanej powyżej struktury danych. W ten sposób otrzymujemy rozwiązanie działające w czasie 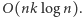 To już lepiej, jednak brakuje nam jeszcze jednego kroku.
To już lepiej, jednak brakuje nam jeszcze jednego kroku.
Główną przeszkodę na drodze do efektywnego rozwiązania stanowi sztywne ograniczenie na liczbę zdjęć, które można wykonać. Przyjmijmy na chwilę, że zadanie sformułowane jest nieco inaczej, a mianowicie wykonanie każdego zdjęcia wiąże się z kosztem 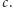 W tej sytuacji nie potrzebujemy już tablicy dwuwymiarowej. Oznaczmy przez
W tej sytuacji nie potrzebujemy już tablicy dwuwymiarowej. Oznaczmy przez ![|d[i]](/math/temat/informatyka/algorytmy/2017/03/27/Obcy/2x-f64884933c77827ad643817aa7f637ee0c427ca5-im-33,33,33-FF,FF,FF.gif) minimalny koszt rozwiązania pokrywającego pierwsze
minimalny koszt rozwiązania pokrywającego pierwsze 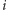 przedziałów. Modyfikując poprzedni wzór, otrzymujemy:
przedziałów. Modyfikując poprzedni wzór, otrzymujemy:
![2 2 d[i] = m0iDns@id[s] +(pi − ls+1) −(max(0, (ps − ls+1))) + c.](/math/temat/informatyka/algorytmy/2017/03/27/Obcy/4x-f64884933c77827ad643817aa7f637ee0c427ca5-dm-33,33,33-FF,FF,FF.gif)
Teraz wystarczy użyć algorytmu analogicznego do tego powyżej. Do obliczenia mamy jednak jedynie 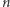 wartości, dlatego poszukiwaną wartość
wartości, dlatego poszukiwaną wartość ![|d[n]](/math/temat/informatyka/algorytmy/2017/03/27/Obcy/6x-f64884933c77827ad643817aa7f637ee0c427ca5-im-33,33,33-FF,FF,FF.gif) obliczyć możemy w czasie
obliczyć możemy w czasie 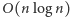 i, jak się za chwilę okaże, przyda się to nam do zaprezentowania ostatecznego rozwiązania.
i, jak się za chwilę okaże, przyda się to nam do zaprezentowania ostatecznego rozwiązania.
Wróćmy do pierwotnego problemu i oznaczmy przez 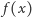 minimalny koszt rozwiązania, w którym wykonujemy dokładnie
minimalny koszt rozwiązania, w którym wykonujemy dokładnie  zdjęć. Naszym zadaniem jest wyznaczenie wartości
zdjęć. Naszym zadaniem jest wyznaczenie wartości 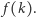 Klucz do rozwiązania stanowi wypukłość funkcji
Klucz do rozwiązania stanowi wypukłość funkcji 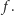 Oznacza to tyle, że przez każdy punkt wykresu
Oznacza to tyle, że przez każdy punkt wykresu 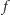 można poprowadzić taką prostą
można poprowadzić taką prostą 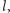 by cały wykres znalazł się ponad prostą
by cały wykres znalazł się ponad prostą 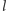 lub na niej. Możemy też spojrzeć na tę własność od innej strony: zwiększanie limitu zdjęć
lub na niej. Możemy też spojrzeć na tę własność od innej strony: zwiększanie limitu zdjęć 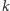 zmniejsza koszt rozwiązania, jednak zysk z każdego kolejnego dodatkowego zdjęcia jest coraz mniejszy. Dowód tej własności jest dosyć skomplikowany i techniczny (a przynajmniej dowód znany autorowi tego tekstu), dlatego nie będziemy go tu podawać. Czytelnikom, którzy chcieliby zdobyć choćby minimalne przekonanie o prawdziwości tej własności, polecamy wykonanie kilku eksperymentów na kartce.
zmniejsza koszt rozwiązania, jednak zysk z każdego kolejnego dodatkowego zdjęcia jest coraz mniejszy. Dowód tej własności jest dosyć skomplikowany i techniczny (a przynajmniej dowód znany autorowi tego tekstu), dlatego nie będziemy go tu podawać. Czytelnikom, którzy chcieliby zdobyć choćby minimalne przekonanie o prawdziwości tej własności, polecamy wykonanie kilku eksperymentów na kartce.
Rys. 4
Algorytm opiszemy nietypowo, zaczynając od graficznej interpretacji jego działania (patrz rysunek 4). Naszym celem jest wyznaczenie wartości 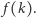 Na początku rysujemy wykres funkcji
Na początku rysujemy wykres funkcji 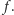 Następnie rysujemy prostą
Następnie rysujemy prostą 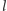 poniżej wykresu
poniżej wykresu 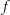 i przesuwamy
i przesuwamy 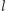 do góry (zachowując jej nachylenie) do momentu, gdy dotknie ona wykresu
do góry (zachowując jej nachylenie) do momentu, gdy dotknie ona wykresu 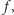 tj. napotka pewien punkt
tj. napotka pewien punkt 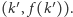 Naszym celem jest tak dobrać nachylenie prostej
Naszym celem jest tak dobrać nachylenie prostej 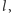 by trafić w punkt
by trafić w punkt 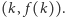 Wypukłość funkcji
Wypukłość funkcji 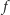 pozwala nam zastosować wyszukiwanie binarne. Jeśli prosta
pozwala nam zastosować wyszukiwanie binarne. Jeśli prosta 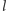 trafia w punkt
trafia w punkt 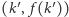 i
i 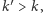 z wypukłości funkcji
z wypukłości funkcji 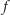 wiemy, że jej współczynnik kierunkowy (wyznaczający nachylenie) jest zbyt duży. W przeciwnym razie
wiemy, że jej współczynnik kierunkowy (wyznaczający nachylenie) jest zbyt duży. W przeciwnym razie 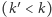 współczynnik jest za mały. Dzięki temu w
współczynnik jest za mały. Dzięki temu w 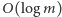 iteracjach takiego algorytmu możemy znaleźć współczynnik kierunkowy, dla którego prosta
iteracjach takiego algorytmu możemy znaleźć współczynnik kierunkowy, dla którego prosta 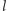 trafi w
trafi w 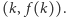
Pozostaje powiedzieć, jak zrealizować jedną iterację powyższego algorytmu. Rozważmy prostą o równaniu 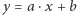 i ustalmy nachylenie tej prostej, czyli wartość współczynnika kierunkowego
i ustalmy nachylenie tej prostej, czyli wartość współczynnika kierunkowego 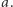 Wówczas szukamy najmniejszej wartości
Wówczas szukamy najmniejszej wartości 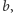 dla której prosta przechodzi przez pewien punkt
dla której prosta przechodzi przez pewien punkt 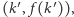 czyli
czyli 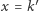 a
a 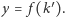 Innymi słowy, szukamy najmniejszej wartości
Innymi słowy, szukamy najmniejszej wartości 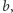 dla której
dla której 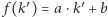 dla pewnego
dla pewnego 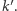 To z kolei jest równoważne ze znalezieniem minimum funkcji
To z kolei jest równoważne ze znalezieniem minimum funkcji 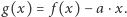
Przyjrzyjmy się bliżej funkcji 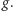 Wartość
Wartość 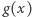 oznacza koszt rozwiązania używającego
oznacza koszt rozwiązania używającego 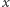 kwadratów pomniejszony o
kwadratów pomniejszony o 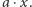 Zatem minimum
Zatem minimum 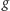 to koszt optymalnego rozwiązania, jeśli wykonanie każdego zdjęcia kosztuje nas
to koszt optymalnego rozwiązania, jeśli wykonanie każdego zdjęcia kosztuje nas 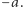 Koszt ten, jak przed chwilą pokazaliśmy, potrafimy obliczyć w czasie
Koszt ten, jak przed chwilą pokazaliśmy, potrafimy obliczyć w czasie 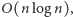 co daje nam rozwiązanie zadania w czasie
co daje nam rozwiązanie zadania w czasie