Jak się pozbyć losowości?
W informatyce losowość jest bardzo przydatna. Często bardzo ułatwia rozumowania, pozwala na piękne i klarowne argumenty używające, na przykład, metody probabilistycznej. Nieraz łatwo znaleźć algorytm używający losowości (randomizowany) i działający szybko, podczas gdy znalezienie szybkiego algorytmu deterministycznego jest trudne lub w ogóle takiego nie znamy. Z losowością jest jednak pewien problem...
Chciałoby się wiedzieć coś na pewno, a nie tylko z dużą dozą prawdopodobieństwa. Szczęśliwie okazuje się, że czasami da się tę losowość wprowadzić, a potem wyeliminować. Ta ostatnia operacja, eliminacja losowości, nazywa się derandomizacją.
Przedstawimy dwie metody derandomizacji. Zrobimy to na przykładzie, choć użyte techniki będą zdecydowanie bardziej ogólne. Rozważmy graf 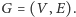 Dla podzbioru wierzchołków
Dla podzbioru wierzchołków 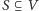 nazwiemy jego cięciem zbiór
nazwiemy jego cięciem zbiór 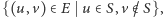 czyli zbiór krawędzi, które mają dokładnie jeden koniec w
czyli zbiór krawędzi, które mają dokładnie jeden koniec w 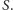 Problem znajdowania
Problem znajdowania 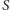 o największym cięciu jest NP-zupełny. Rozważmy jednak podobny problem: znajdowania
o największym cięciu jest NP-zupełny. Rozważmy jednak podobny problem: znajdowania 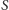 takiego, że jego cięcie jest wielkości co najmniej połowy zbioru wszystkich krawędzi, czyli
takiego, że jego cięcie jest wielkości co najmniej połowy zbioru wszystkich krawędzi, czyli 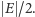
Na pierwszy rzut oka nie jest wcale jasne, czy taki 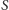 istnieje. A więc na rozgrzewkę udowodnijmy to. Zachęcamy Czytelników do samodzielnej próby przed przeczytaniem rozwiązania. Rozwiązanie zaś jest zadziwiająco proste. Wylosujmy
istnieje. A więc na rozgrzewkę udowodnijmy to. Zachęcamy Czytelników do samodzielnej próby przed przeczytaniem rozwiązania. Rozwiązanie zaś jest zadziwiająco proste. Wylosujmy 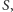 to znaczy każdy wierzchołek wrzućmy niezależnie do
to znaczy każdy wierzchołek wrzućmy niezależnie do 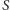 z prawdopodobieństwem
z prawdopodobieństwem 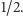 Wówczas każda krawędź z
Wówczas każda krawędź z 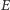 będzie należała do cięcia
będzie należała do cięcia 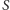 z prawdopodobieństwem
z prawdopodobieństwem 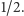 A zatem średnia wielkość cięcia
A zatem średnia wielkość cięcia 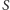 to
to 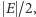 czyli na pewno musi istnieć
czyli na pewno musi istnieć 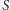 taki, że jego cięcie ma wielkość przynajmniej
taki, że jego cięcie ma wielkość przynajmniej 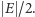 Powyższy dowód jest jednak niekonstruktywny, nie wynika z niego wcale, jak takie cięcie znaleźć. Oczywiście, możemy przejrzeć wszystkie możliwe zbiory
Powyższy dowód jest jednak niekonstruktywny, nie wynika z niego wcale, jak takie cięcie znaleźć. Oczywiście, możemy przejrzeć wszystkie możliwe zbiory 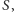 ale to zajmie czas rzędu
ale to zajmie czas rzędu 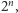 gdzie
gdzie 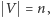 a my chcemy znaleźć algorytm wielomianowy względem
a my chcemy znaleźć algorytm wielomianowy względem 
Podamy dwie metody. Pierwsza nazywa się metodą warunkowych wartości oczekiwanych. Przypuśćmy, że przejrzeliśmy już pewien zbiór wierzchołków 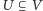 i dla każdego z nich zdecydowaliśmy, czy będzie on należał do
i dla każdego z nich zdecydowaliśmy, czy będzie on należał do 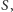 czy nie. Jaka jest średnia wielkość cięcia
czy nie. Jaka jest średnia wielkość cięcia 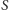 po tym ustaleniu? Przez
po tym ustaleniu? Przez 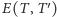 oznaczmy zbiór krawędzi między zbiorami
oznaczmy zbiór krawędzi między zbiorami 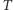 i
i 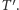 Na razie wiemy, że do cięcia na pewno będzie należała każda krawędź z
Na razie wiemy, że do cięcia na pewno będzie należała każda krawędź z 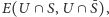 gdzie
gdzie 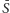 to dopełnienie zbioru
to dopełnienie zbioru 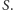 Jeśli chodzi o krawędzie jeszcze nieustalone, to każda krawędź z
Jeśli chodzi o krawędzie jeszcze nieustalone, to każda krawędź z 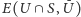 będzie należała do cięcia z prawdopodobieństwem
będzie należała do cięcia z prawdopodobieństwem 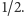 A zatem średnia wartość cięcia po ustaleniu, co się stanie z wierzchołkami z
A zatem średnia wartość cięcia po ustaleniu, co się stanie z wierzchołkami z 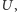 wynosi
wynosi 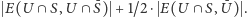 Umiemy to obliczyć w czasie wielomianowym, znając
Umiemy to obliczyć w czasie wielomianowym, znając 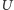 oraz decyzję odnośnie
oraz decyzję odnośnie 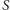 na nim, czyli
na nim, czyli 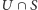 oraz
oraz 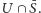 Teraz już tylko krok do rozwiązania. Gdy bowiem decydujemy o pierwszym wierzchołku, czy wrzucić go do
Teraz już tylko krok do rozwiązania. Gdy bowiem decydujemy o pierwszym wierzchołku, czy wrzucić go do 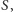 czy nie, to obliczamy, jaka będzie średnia wartość cięcia w obu przypadkach. Ponieważ średnia z tych dwóch liczb jest większa lub równa
czy nie, to obliczamy, jaka będzie średnia wartość cięcia w obu przypadkach. Ponieważ średnia z tych dwóch liczb jest większa lub równa 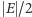 (w tym przypadku równa), to jedna z nich też będzie większa lub równa. Wybieramy więc tę lepszą opcję i zabieramy się za drugi element. Przy dorzucaniu każdego nowego elementu wybieramy tę opcję, która daje większą średnią i w ten sposób po podjęciu decyzji dla wszystkich elementów
(w tym przypadku równa), to jedna z nich też będzie większa lub równa. Wybieramy więc tę lepszą opcję i zabieramy się za drugi element. Przy dorzucaniu każdego nowego elementu wybieramy tę opcję, która daje większą średnią i w ten sposób po podjęciu decyzji dla wszystkich elementów 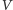 otrzymujemy pewien zbiór
otrzymujemy pewien zbiór 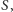 którego cięcie będzie większe lub równe
którego cięcie będzie większe lub równe 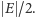
Drugie rozwiązanie jest jeszcze bardziej zaskakujące. Zauważmy, że tak naprawdę nie potrzebujemy wcale, by każdy wierzchołek z 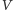 był brany do
był brany do 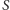 niezależnie. Do tego, by każda krawędź
niezależnie. Do tego, by każda krawędź 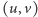 znalazła się w cięciu
znalazła się w cięciu 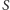 z prawdopodobieństwem
z prawdopodobieństwem 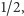 wystarczy, by wierzchołki
wystarczy, by wierzchołki  i
i  były wzięte do
były wzięte do 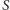 niezależnie , czyli wystarczy nam, by wybory były parami niezależne. A to jest dużo słabsze wymaganie! Co więcej, okazuje się, że z
niezależnie , czyli wystarczy nam, by wybory były parami niezależne. A to jest dużo słabsze wymaganie! Co więcej, okazuje się, że z 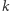 niezależnych zmiennych losowych
niezależnych zmiennych losowych 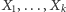 o wartościach w
o wartościach w 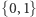 można łatwo skonstruować
można łatwo skonstruować 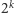 zmiennych losowych parami niezależnych o wartościach w
zmiennych losowych parami niezależnych o wartościach w 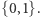 Po prostu dla każdego podzbioru
Po prostu dla każdego podzbioru 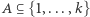 zmienna
zmienna 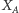 jest zdefiniowana jako xor (alternatywa wykluczająca) zmiennych
jest zdefiniowana jako xor (alternatywa wykluczająca) zmiennych 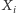 takich, że
takich, że 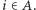 Nietrudno zauważyć, że dla dowolnych
Nietrudno zauważyć, że dla dowolnych 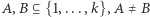 zmienne
zmienne 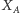 i
i 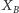 są niezależne. Dla uproszczenia przyjmijmy, że
są niezależne. Dla uproszczenia przyjmijmy, że 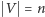 jest potęgą dwójki. A więc nasz algorytm możemy zamienić na taki, który losuje najpierw
jest potęgą dwójki. A więc nasz algorytm możemy zamienić na taki, który losuje najpierw 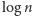 bitów
bitów 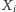 dla
dla 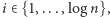 a potem gdy podejmuje losową decyzję, czy wrzucić jakiś wierzchołek z
a potem gdy podejmuje losową decyzję, czy wrzucić jakiś wierzchołek z 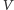 do zbioru
do zbioru 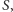 korzysta ze zmiennych
korzysta ze zmiennych 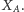 Taki algorytm też w średnim przypadku skonstruuje cięcie wielkości
Taki algorytm też w średnim przypadku skonstruuje cięcie wielkości 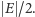 Zauważmy jednak, że zamiast losować te
Zauważmy jednak, że zamiast losować te 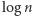 wartości możemy po prostu sprawdzić wszystkie możliwości ich wylosowań, których jest
wartości możemy po prostu sprawdzić wszystkie możliwości ich wylosowań, których jest 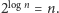 Czyli faktycznie otrzymaliśmy wielomianowy algorytm deterministyczny: przegląda on wszystkie możliwości na
Czyli faktycznie otrzymaliśmy wielomianowy algorytm deterministyczny: przegląda on wszystkie możliwości na 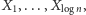 dla każdej symuluje działanie losowego algorytmu, a na koniec wybiera najlepsze rozwiązanie.
dla każdej symuluje działanie losowego algorytmu, a na koniec wybiera najlepsze rozwiązanie.