Złożoność algorytmów teorioliczbowych
Rozważmy następujący algorytm:

Jak łatwo sprawdzić, podany kod zwraca najmniejszy nietrywialny czynnik podanej na wejściu liczby 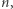 bądź 0 - gdy takiego czynnika nie ma (bo np.
bądź 0 - gdy takiego czynnika nie ma (bo np. 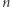 jest liczbą pierwszą).
jest liczbą pierwszą).
Zastanówmy się, jaka jest złożoność podanego programu. Pętla while wykona co najwyżej 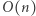 obrotów. W pojedynczym jej wykonaniu niemal wszystkie operacje mają koszt stały, poza operacją while której koszt możemy bardzo zgrubnie oszacować z góry przez
obrotów. W pojedynczym jej wykonaniu niemal wszystkie operacje mają koszt stały, poza operacją while której koszt możemy bardzo zgrubnie oszacować z góry przez 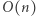 (w rzeczywistości można łatwo osiągnąć
(w rzeczywistości można łatwo osiągnąć 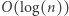 ). Oznacza to, że cały algorytm działa w czasie nie większym niż
). Oznacza to, że cały algorytm działa w czasie nie większym niż 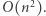
Czy oznacza to, że właśnie pokazaliśmy wielomianowy algorytm na szukanie nietrywialnych czynników? Rozkład nawet dużych liczb na czynniki pierwsze już nie jest dla nas kłopotem?
Oczywiście, nic z tych rzeczy.
Nieporozumienie bierze się z problemu z ustaleniem, co jest parametrem, względem którego liczymy złożoność programów komputerowych. Otóż parametrem jest dla nas zawsze rozmiar danych, ale rozumiany jako długość napisu reprezentującego wejście. Konkretniej: 1000000000 ma dla nas rozmiar "dziesięć", a nie "miliard"...
Wracając do naszego algorytmu: jeśli rozmiar danych to 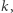 to wówczas liczba
to wówczas liczba 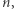 którą reprezentują te dane jest rzędu
którą reprezentują te dane jest rzędu 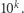 Skoro więc oszacowaliśmy czas działania algorytmu przez
Skoro więc oszacowaliśmy czas działania algorytmu przez 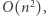 to w języku rozmiaru danych przekłada się to na
to w języku rozmiaru danych przekłada się to na 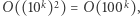 czyli jest jednak wykładniczy od
czyli jest jednak wykładniczy od 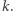
Potencjalny algorytm wielomianowy na rozkład na czynniki musiałby więc być pewnie nieco bardziej wyrafinowany...