Informatyczny kącik olimpijski
Coś się popsuło
W noworocznym kąciku omówimy zadanie Wykrywanie wrednej usterki pochodzące z zeszłorocznej Międzynarodowej Olimpiady Informatycznej, która odbyła się w Kazaniu (Rosja). Autorzy zadania oczekują od nas, że pomożemy zdiagnozować usterkę, która wkradła się do bazy danych zaimplementowaną przez niefrasobliwego inżyniera Ilszata.
Baza danych inż. Ilszata miała działać bardzo prosto. Zaprojektowane były tylko dwie operacje. Pierwsza operacja add(x) miała za zadanie dodanie do bazy danych nowego elementu x, o którym zakładamy, że jest zawsze ciągiem 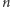 bitów (przy czym dodatkowo możemy przyjąć, że
bitów (przy czym dodatkowo możemy przyjąć, że  jest potęgą dwójki). Druga operacja check(x) powinna sprawdzać, czy x znajduje się w bazie, czy też nie.
jest potęgą dwójki). Druga operacja check(x) powinna sprawdzać, czy x znajduje się w bazie, czy też nie.
Jako się rzekło, nie wszystko poszło według z góry ustalonego planu.
Okazało się, że operacja check(x) działa zupełnie poprawnie, natomiast operacja add(x) ma w sobie dziwnego buga (oszibkę?). Otóż, po wywołaniu add(x), zamiast ciągu x, do bazy danych dodawany jest ciąg 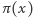 dla pewnej (nieznanej nam) permutacji
dla pewnej (nieznanej nam) permutacji 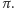 Celem zadania jest właśnie ustalenie tej permutacji, poprzez wykonanie pewnego ciągu operacji na (początkowo pustej) bazie danych. Dodatkowym utrudnieniem jest założenie, że najpierw możemy wykonywać wyłącznie operacje typu add, a później wyłącznie operacje typu check. Innymi słowy: nie możemy przeplatać różnych typów operacji.
Celem zadania jest właśnie ustalenie tej permutacji, poprzez wykonanie pewnego ciągu operacji na (początkowo pustej) bazie danych. Dodatkowym utrudnieniem jest założenie, że najpierw możemy wykonywać wyłącznie operacje typu add, a później wyłącznie operacje typu check. Innymi słowy: nie możemy przeplatać różnych typów operacji.
Zaprezentujemy dwa rozwiązania: pierwsze wymaga wykonania 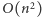 operacji, drugie (maksymalnie punktowane):
operacji, drugie (maksymalnie punktowane): 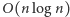 operacji.
operacji.
W pierwszym podejściu zaczynamy od wykonania 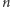 operacji add na następujących elementach (wykładnik oznacza krotność powtórzenia ostatniego symbolu):
operacji add na następujących elementach (wykładnik oznacza krotność powtórzenia ostatniego symbolu): 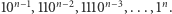 Następnie przechodzimy do fazy check-ów i zaczynamy od zapytania bazy danych o elementy:
Następnie przechodzimy do fazy check-ów i zaczynamy od zapytania bazy danych o elementy: 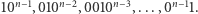 Oczywiście dokładnie raz otrzymamy odpowiedź pozytywną, dzięki czemu ustalimy na co zamienił się element
Oczywiście dokładnie raz otrzymamy odpowiedź pozytywną, dzięki czemu ustalimy na co zamienił się element 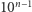 (jedyny z jedną jedynką), czyli poznamy
(jedyny z jedną jedynką), czyli poznamy 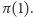 Czas na kolejne pytania. Tym razem pytamy (kolejno) o wszystkie ciągi zawierające dwie jedynki, z których jedna jest zawsze na pozycji
Czas na kolejne pytania. Tym razem pytamy (kolejno) o wszystkie ciągi zawierające dwie jedynki, z których jedna jest zawsze na pozycji 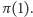 Podobnie jak poprzednio dokładnie raz otrzymamy odpowiedź pozytywną, co pozwoli na ustalenie obrazu
Podobnie jak poprzednio dokładnie raz otrzymamy odpowiedź pozytywną, co pozwoli na ustalenie obrazu 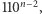 a ten określi wartość
a ten określi wartość 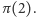 Postępując dalej w ten sposób ustalamy w kolejnych krokach kolejne wartości
Postępując dalej w ten sposób ustalamy w kolejnych krokach kolejne wartości 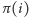 dla
dla 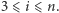 Każdy krok nie wymaga więcej niż
Każdy krok nie wymaga więcej niż 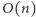 zapytań, a więc łączny czas działania szacuje się z góry, zgodnie z obietnicą, przez
zapytań, a więc łączny czas działania szacuje się z góry, zgodnie z obietnicą, przez 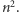
Rozwiązanie szybsze opiera się na zastosowaniu popularnej (znacznie dłużej niż teoria algorytmów) metody "dziel i zwyciężaj". Idea polega na ustaleniu obrazów pierwszej i drugiej połówki indeksów permutacji (czyli zbiorów 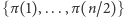 oraz
oraz 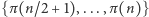 ) a następnie przeanalizowanie (rekurencyjnie) każdej z połówek niezależnie od siebie. Aby ten pomysł zrealizować w ramach założeń zadania (nie możemy przeplatać add-ów i check-ów!) potrzeba pewnej zręczności.
) a następnie przeanalizowanie (rekurencyjnie) każdej z połówek niezależnie od siebie. Aby ten pomysł zrealizować w ramach założeń zadania (nie możemy przeplatać add-ów i check-ów!) potrzeba pewnej zręczności.
Zacznijmy od definicji pewnej rodziny zbiorów. Niech 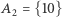 oraz niech
oraz niech 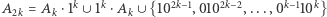 (patrz przykład na marginesie).
(patrz przykład na marginesie).
Właściwe rozwiązanie zaczyna się od wykonania operacji add na wszystkich elementach zbioru 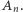 Odtąd możemy już wykonywać wyłącznie operacje check. Zaczynamy od zapytania o wszystkie elementy postaci
Odtąd możemy już wykonywać wyłącznie operacje check. Zaczynamy od zapytania o wszystkie elementy postaci 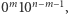 czyli te z jedną jedynką. Widzimy, że w zbiorze
czyli te z jedną jedynką. Widzimy, że w zbiorze 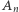 znajduje się dokładnie
znajduje się dokładnie 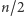 elementów z jedną jedynką, a więc i tyle dostaniemy pozytywnych odpowiedzi, przy okazji ustalając na co "przechodzą" obie połówki permutacji
elementów z jedną jedynką, a więc i tyle dostaniemy pozytywnych odpowiedzi, przy okazji ustalając na co "przechodzą" obie połówki permutacji 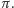 W tym miejscu chciałoby się po prostu napisać i dalej rekurencyjnie. Jest tak w istocie, ale trzeba mieć w głowie pewną subtelność. Otóż zbiór elementów, które włożyliśmy do bazy danych został już raz na zawsze ustalony. Trzeba się więc upewnić, czy w wywołaniach rekurencyjnych nie przeszkadzać nam będą jakieś inne elementy z innych faz oraz jak właściwie tłumaczyć zapytania z faz mniejszego rozmiaru na prawdziwe zapytania, gdzie mamy jedno
W tym miejscu chciałoby się po prostu napisać i dalej rekurencyjnie. Jest tak w istocie, ale trzeba mieć w głowie pewną subtelność. Otóż zbiór elementów, które włożyliśmy do bazy danych został już raz na zawsze ustalony. Trzeba się więc upewnić, czy w wywołaniach rekurencyjnych nie przeszkadzać nam będą jakieś inne elementy z innych faz oraz jak właściwie tłumaczyć zapytania z faz mniejszego rozmiaru na prawdziwe zapytania, gdzie mamy jedno  ustalone z góry.
ustalone z góry.
Zakończę sakramentalnym: da się, ale ze szczegółami pozostawiam Czytelnika samego.
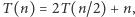 co oznacza, że
co oznacza, że