Pół szklanki mocnego kodu
Co ja tu widzę...
Zadziwiające, jak szybko uczenie maszynowe trafiło pod strzechy! Jeszcze nie tak dawno wymagało biegłości w programowaniu, znajomości takich konceptów, jak funkcja aktywacji, rozkład macierzy względem wartości szczególnych, optymalizacja dla funkcji niegładkich itp. Aby wszystko to zadziałało, niezbędny też był dostęp do dostatecznie dobrych danych treningowych i morza czasu obliczeniowego… A dziś?
Teraz możemy, w kilku linijkach mocnego kodu, wykorzystać gotowe, uprzednio wyuczone moduły - na przykład do rozpoznania, jaki obiekt przedstawia zdjęcie. Oczywiście, to wszystko jest możliwe pod warunkiem, że mamy dostęp do dostatecznie mądrego pakietu… Wybierzemy więc potężny Tensorflow od samego Google Brain. Sposób jego instalacji na komputerze jest bardzo dokładnie opisany na stronie domowej projektu (ja skorzystałem z instalacji w wirtualnym środowisku Pythona na Ubuntu). Poniższy kod w Pythonie rozpoznaje obiekt ze zdjęcia (u nas: znajdującego się w pliku image.jpg):

Na podstawie www.keras.io/applications/

Cabot Tower w miejscowości St. John's, Kanada (plik image.jpg).
Na początku programu (linie 1-2) wybieramy z Tensorflow tylko te funkcje, które będą nam potrzebne. Należą one do modułów pakietu Keras (keras.io), który dostarcza interfejs bardzo wysokiego poziomu, m.in. do aplikacji takich, jak InceptionV3. Notabene, inspiracja dla powyższego kodu pochodzi z dokumentacji pakietu. InceptionV3 to wcześniej wytrenowana konwolucyjna sieć neuronowa (Keras daje też dostęp do kilku innych), która przy pierwszym uruchomieniu funkcji zostanie pobrana z internetu - i dalej już cały proces rozpoznawania będzie odbywał się u nas na komputerze, bez korzystania z usług w chmurze obliczeniowej. Sieć neuronowa Inception-v3 została nauczona rozpoznawania obrazów, czyli przypisywania im prawdopodobieństwa przynależności do każdej z 1000 z góry ustalonych klas, w rodzaju: "samochód", "bikini", "pies" itp. Podobno poziom trafności jej wskazań jest podobny do osiąganego przez ludzi!
Najważniejsza część programu - rozpoznanie obrazu - składa się zaledwie z trzech linii 9-11:

Najpierw inicjalizujemy sieć neuronową (z domyślnymi parametrami). Ponieważ będziemy klasyfikować zdjęcia, musimy przygotować je do postaci odpowiedniej dla Kerasa. Mała funkcja pomocnicza prepare_image_iv3 (linie 4-7) zwraca wstępnie spreparowane zdjęcie z pliku (m.in. nadaje mu odpowiednie rozmiary, gdyż Inception-v3 oczekuje obrazu o rozmiarach 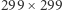 pikseli). Następnie zdjęcie poddajemy dalszej obróbce przez preprocess_input (normalizując i uśredniając dane). Na końcu - w linii 11 - uruchamiamy sieć, która informuje nas, z jakim prawdopodobieństwem zaliczyłaby rozpoznawane obiekty do każdej z klas.
pikseli). Następnie zdjęcie poddajemy dalszej obróbce przez preprocess_input (normalizując i uśredniając dane). Na końcu - w linii 11 - uruchamiamy sieć, która informuje nas, z jakim prawdopodobieństwem zaliczyłaby rozpoznawane obiekty do każdej z klas.
Wyniki klasyfikacji drukujemy (linie 13-14), przebiegając kolejne elementy listy zwróconej przez funkcję decode_predictions; domyślnie zostanie podanych pięć najbardziej prawdopodobnych typowań. Oto wynik dla naszego zdjęcia:
0.84: castle
0.02: palace
0.01: monastery
0.01: bell_cote
0.01: church
Nieźle, prawda? Program stwierdził, że z prawdopodobieństwem 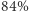 zdjęcie przedstawia zamek, z czym z pewnością zgodziłaby się większość z nas. Jednak nie zawsze będzie tak dobrze, a czasem nawet rezultat będzie całkiem bez sensu. Zachęcam do eksperymentowania: z różnymi zdjęciami i z różnymi klasyfikatorami dostępnymi w Keras!
zdjęcie przedstawia zamek, z czym z pewnością zgodziłaby się większość z nas. Jednak nie zawsze będzie tak dobrze, a czasem nawet rezultat będzie całkiem bez sensu. Zachęcam do eksperymentowania: z różnymi zdjęciami i z różnymi klasyfikatorami dostępnymi w Keras!
Ciekawe, że sieć Inception-v3 możemy także douczyć rozpoznawać obrazy według naszych własnych kryteriów (od razu pomyślałem o automatycznym rozpoznawaniu znajomych: coś podobnego potrafi już np. aplikacja Zdjȩcia w Windows 10). Jak to zrobić po swojemu - można przeczytać na stronach Tensorflow poświęconych image recognition. Co prawda tak rozbudowany kod zajmie trochę więcej niż pół strony, ale można się przy tym sporo dowiedzieć!
Zapewne niektórzy Czytelnicy czują pewien niedosyt, widząc opisy kategorii po angielsku ( "castle" zamiast "zamek"). Czemu więc nie przetłumaczyć w automatyczny sposób wyników z języka, w którym Czesław Miłosz wykładał, na język, w którym pisał wiersze - korzystając na przykład z Google Translate?
PS W rzeczywistości obiekt na zdjęciu… niestety nie jest zamkiem (co łatwo sprawdzić w Wikipedii), ale - nie da się ukryć - bardzo przypomina zamek. Ja w każdym razie dałbym się nabrać.