Programowanie na platformie CUDA
Dziesięć lat temu kolejne generacje procesorów charakteryzowały się wykładniczo rosnącą częstotliwością taktowania. Teraz ta sytuacja uległa zmianie. Obecnie to liczba rdzeni w jednym procesorze zaczyna rosnąć wykładniczo. W użytku są już procesory firmy Intel dla zwyczajnych PC-tów mające 8 rdzeni, a co jakiś czas pojawiają się informacje o tym, że niedługo zostanie wyprodukowany procesor o 50 rdzeniach...
Niestety, pisanie programu, który wykorzystuje w pełni moc
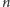 rdzeni,
nie jest dla programisty łatwym zadaniem. Jest to spowodowane dość
uciążliwymi metodami synchronizacji wielu wątków i używanym
modelem pamięci, który jest bardziej przystosowany do programowania
jednowątkowego.
rdzeni,
nie jest dla programisty łatwym zadaniem. Jest to spowodowane dość
uciążliwymi metodami synchronizacji wielu wątków i używanym
modelem pamięci, który jest bardziej przystosowany do programowania
jednowątkowego.
Okazuje się, że w większości współczesnych komputerów znajduje się drugi układ scalony, który od początku był projektowany do obliczeń równoległych. Chodzi o kartę graficzną. Zwyczajowo karta graficzna ma za zadanie obliczyć wartości koloru pojedynczych pikseli na ekranie. Widać, że wyniki poszczególnych obliczeń są niezależne. W tym artykule chciałbym przybliżyć platformę CUDA, która służy do programowania na kartach graficznych firmy NVIDIA. O tym, że warto zastanowić się nad programowaniem na karcie graficznej, może świadczyć następujące porównanie:
- jeden z najlepszych obecnie procesorów Intela – Core i7 980X – kosztuje ok. 1000 dolarów i osiąga moc obliczeniową ok. 100 Gflopsów;
- jedna z najlepszych kart graficznych NVIDIA – GeForce GTX 580 – kosztuje ok. 500 dolarów i oferuje moc obliczeniową ok. 1500 Gflopsów.
Struktura karty graficznej
Karta graficzna składa się (w uproszczeniu) z multiprocesorów, przy czym jeden multiprocesor składa się z 8 lub 16 pojedynczych procesorów i jednej niewielkiej współdzielonej pamięci na cały multiprocesor (pamięć multiprocesora jest szybka, umożliwia jednoczesny odczyt/zapis), oraz jednej dużej pamięci, która jest wspólna dla wszystkich multiprocesorów. Pamięć ta jest o rząd wielkości wolniejsza od pamięci multiprocesora, umożliwia także jednoczesny odczyt/zapis.
Rys. 1 Struktura karty graficznej (część zacieniona) i przepływ danych w pamięci komputera podczas obliczeń.
Standardowo program używający do obliczeń karty graficznej będzie działał według następującego schematu: skopiowanie danych z pamięci komputera do pamięci głównej karty graficznej i dalej do pamięci multiprocesora; wykonanie obliczenia na multiprocesorach; skopiowanie częściowych wyników z pamięci multiprocesora do pamięci głównej karty graficznej i skopiowanie końcowego wyniku do pamięci komputera.
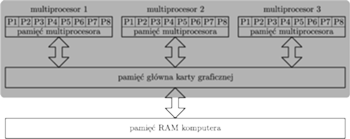
Struktura obliczeń
Rys. 2 Struktura obliczeń.
A teraz ciekawe pytanie: w jaki sposób programista rozdziela zadania między
multiprocesory i procesory? Przypuśćmy, że chcemy wykonać jakieś
duże obliczenie
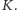 Programista dzieli je na zbiór mniejszych obliczeń:
Programista dzieli je na zbiór mniejszych obliczeń:
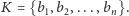 Pojedynczy element obliczenia
Pojedynczy element obliczenia
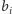 to blok,
który jest z kolei złożony z pojedynczych wątków:
to blok,
który jest z kolei złożony z pojedynczych wątków:

Specyfikacja techniczna platformy CUDA daje następujące gwarancje: każdy blok będzie wykonywany w obrębie jednego multiprocesora; nic nie wiadomo o tym, w jakiej kolejności wykonają się bloki; jeden wątek wykona się na jednym procesorze; w obrębie jednego multiprocesora wykonuje się w danym momencie co najwyżej jeden blok.
Zadaniem programisty jest napisanie kodu pojedynczego wątku. Każdy wątek wykonuje dokładnie ten sam kod, przy czym wątek może sprawdzić, w którym bloku się znajduje, a także jaki ma numer wewnątrz tego bloku. Obliczenie wykonywane przez wątek zależy od tak zdefiniowanych współrzędnych tego wątku.
Należy jeszcze podkreślić, że programista nie specyfikuje dokładnie, na którym procesorze wykona się dany wątek. Zadaniem programisty jest zdefiniować strukturę obliczeń, a przydziałem wątków do procesorów zajmuje się CUDA.
Praktyczny przykład – mnożenie macierzy
Chcemy pomnożyć dwie macierze
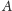 i
i
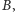 obie wymiaru
obie wymiaru
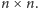 Przez
Przez
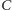 oznaczmy macierz wynikową. Obliczenie macierzy
oznaczmy macierz wynikową. Obliczenie macierzy
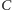 wprost z definicji wymaga wykonania
wprost z definicji wymaga wykonania
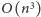 operacji. Używając
platformy CUDA, można zaproponować lepsze rozwiązanie, w którym
wszystkie macierze dzielimy na podmacierze rozmiaru
operacji. Używając
platformy CUDA, można zaproponować lepsze rozwiązanie, w którym
wszystkie macierze dzielimy na podmacierze rozmiaru
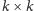 (oznaczamy
je przez
(oznaczamy
je przez
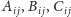 ). Dla uproszczenia analizy założymy, że rozmiar
macierzy
). Dla uproszczenia analizy założymy, że rozmiar
macierzy
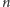 jest wielokrotnością rozmiaru podmacierzy
jest wielokrotnością rozmiaru podmacierzy
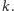 Jeden
blok obliczenia będzie miał za zadanie obliczyć jedną z podmacierzy
Jeden
blok obliczenia będzie miał za zadanie obliczyć jedną z podmacierzy
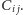 Zauważmy, że
Zauważmy, że
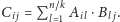 W jednej iteracji
będziemy chcieli obliczyć jeden składnik postaci
W jednej iteracji
będziemy chcieli obliczyć jeden składnik postaci
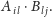 Można to
zrobić następująco.
Można to
zrobić następująco.
- pobieramy do pamięci multiprocesora macierze
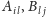 – tę pracę wykonuje pierwszy wątek z każdego
bloku;
– tę pracę wykonuje pierwszy wątek z każdego
bloku;
- równolegle
obliczamy
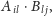 każdej komórce macierzy wynikowej
przyporządkowujemy jeden wątek dpowiedzialny za obliczenie tej
wartości;
każdej komórce macierzy wynikowej
przyporządkowujemy jeden wątek dpowiedzialny za obliczenie tej
wartości;
- dodajemy do wyniku obliczoną wartość
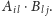
Po wykonaniu obliczeń dla wszystkich
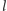 mamy obliczoną podmacierz
mamy obliczoną podmacierz
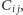 którą możemy zapisać do pamięci głównej karty.
którą możemy zapisać do pamięci głównej karty.

Rys. 3 Schemat mnożenia macierzy. Tutaj
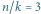 oraz
oraz
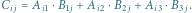
Rys. 3 Schemat mnożenia macierzy. Tutaj
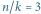 oraz
oraz
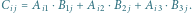
Spróbujmy oszacować złożoność tego rozwiązania. W tym celu przez
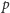 oznaczmy liczbę procesorów wewnątrz jednego multiprocesora,
a przez
oznaczmy liczbę procesorów wewnątrz jednego multiprocesora,
a przez
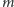 – liczbę multiprocesorów.
– liczbę multiprocesorów.
Przyjrzyjmy się czasowi wykonywania pojedynczego bloku. Przy obliczaniu iloczynu
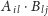 najpierw pobieramy dwie macierze rozmiaru
najpierw pobieramy dwie macierze rozmiaru
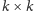 do
pamięci multiprocesora, co zajmuje czas
do
pamięci multiprocesora, co zajmuje czas
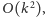 a następnie wykonujemy
a następnie wykonujemy
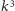 mnożeń, ale to zrównolegla się między
mnożeń, ale to zrównolegla się między
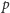 procesorów, koszt
tego wynosi więc
procesorów, koszt
tego wynosi więc
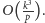 Taki ciąg operacji należy wykonać
dla
Taki ciąg operacji należy wykonać
dla
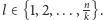 Zatem jeden blok wykonuje się w czasie
Zatem jeden blok wykonuje się w czasie
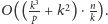
Mamy
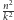 bloków, ich wykonanie zrównoleglamy między
bloków, ich wykonanie zrównoleglamy między
 multiprocesorów, zatem łączny czas to
multiprocesorów, zatem łączny czas to
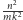 razy
czas wykonania pojedynczego bloku. Daje to złożoność czasową
razy
czas wykonania pojedynczego bloku. Daje to złożoność czasową
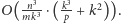 Przyjmując, że
Przyjmując, że
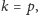 co jest możliwe,
gdyż to programista dobiera wartość
co jest możliwe,
gdyż to programista dobiera wartość
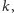 daje to złożoność
daje to złożoność
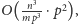 czyli
czyli
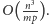 W ten sposób klasyczną
złożoność
W ten sposób klasyczną
złożoność
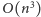 podzieliliśmy przez
podzieliliśmy przez
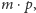 czyli liczbę
procesorów. We wspomnianej wcześniej karcie GeForce GTX 580
mamy
czyli liczbę
procesorów. We wspomnianej wcześniej karcie GeForce GTX 580
mamy
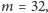
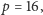 czyli programista ma do dyspozycji
czyli programista ma do dyspozycji
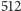 procesorów. To daje duże możliwości zrównoleglania.
procesorów. To daje duże możliwości zrównoleglania.
Czy przyszłość programowania leży w równoległości?
Jest cała lista problemów związanych z programowaniem równoległym, jak np.: mała liczba doświadczonych programistów; wyższy niż w przypadku programowania jednowątkowego poziom skomplikowania; część algorytmów ciężko się zrównolegla (np. nie jest znany dobry równoległy algorytm sprawdzania, czy w danym grafie dwudzielnym jest doskonałe skojarzenie); błędy typu race condition, gdy więcej niż jeden wątek jednocześnie zapisuje w danym miejscu w pamięci.
Z drugiej strony programiści chcieliby, aby ich programy działały szybko. Podnoszenie wydajności pojedynczego rdzenia nie odbywa się w takim tempie jak kiedyś, można więc przypuszczać, że do dalszego poprawiania wydajności oprogramowania potrzebne jest odrzucenie modelu programowania z jednym procesorem i myślenie w sposób równoległy. NVIDIA CUDA jest jednym z ciekawszych modeli oferujących możliwość programowania współbieżnego. Wprowadza to za cenę jednej zasadniczej nowości: programiści muszą nauczyć się dzielić obliczenia tworzonego oprogramowania na możliwie niezależne kawałki. Nie jest to takie łatwe, bo całkowicie zmienia sposób myślenia o programowaniu.